BidirLM Omni 2.5B
BidirLM/BidirLM-Omni-2.5B-Embedding
published Apr 2026 · updated May 2026
BidirLM Omni 2.5B is a bidirectional omnimodal embed model that jointly embeds text, images, and audio into a shared 2048-dimensional representation space for cross-modal retrieval and similarity.
specs
| Task | Multimodal embeddings (text, image, audio) |
| Architecture | Custom bidirectional omnimodal encoder |
| Parameters | 2.5B |
about this model
BidirLM-Omni-2.5B-Embedding is a 2.5B parameter bidirectional encoder that jointly embeds text, images, and audio into a shared 2048-dimensional representation space, enabling cross-modal retrieval, semantic similarity, clustering, and classification across all three modalities.
The model supports over 119 languages (inherited from the Qwen3 base and reinforced through contrastive training with 87 languages) and accepts a 32k token context for text. Images of any size and aspect ratio are resized internally; audio at any sample rate is resampled to 16 kHz. All modalities produce embeddings directly comparable via cosine similarity.
Key architectural details: the model uses mean pooling across all modalities, requires trust_remote_code=True due to its custom bidirectional omnimodal architecture, and should be run with cuDNN > 9.20.0 to avoid a known Conv3D performance regression on H100 GPUs.
Benchmark performance is illustrated below across MTEB Multilingual V2, MIEB (lite), and MAEB (beta):
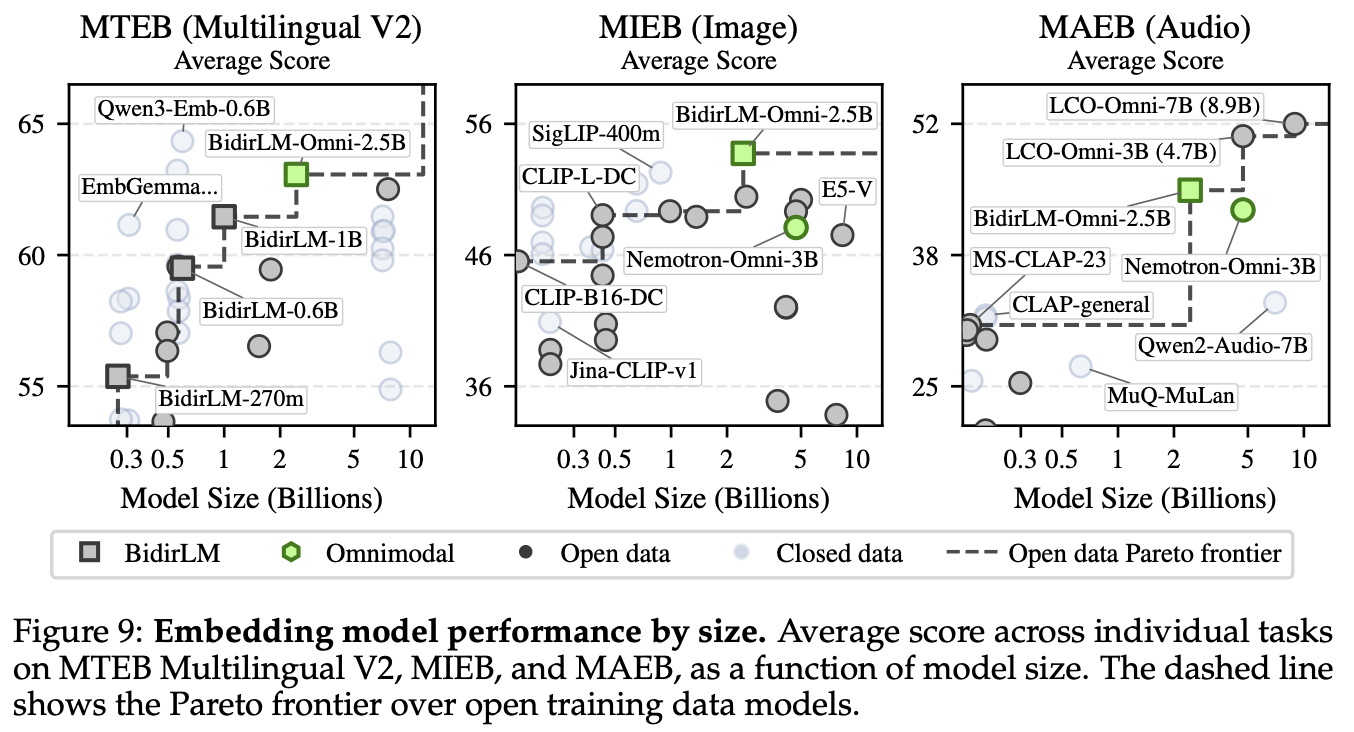
The model is based on the BidirLM architecture described in arXiv:2604.02045, which transforms causal LLMs into bidirectional encoders through a combination of prior masking, linear weight merging, and multi-domain data mixture training.
best for
- ·Cross-modal text-image and text-audio retrieval
- ·Multimodal semantic similarity and clustering
- ·Fine-tuning for sequence classification (e.g., NLI) and token classification (e.g., NER)
FAQ
The model uses mean pooling across all modalities, handled automatically with Sentence Transformers.
Yes, the model requires trust_remote_code=True because it uses a custom bidirectional omnimodal architecture.
Yes, text, image, and audio embeddings live in the same 2048-dimensional space and can be compared directly using cosine similarity.
Any sample rate is accepted; the model resamples internally to 16 kHz. Input formats: np.ndarray, list[float], or dict with "array" and "sampling_rate".
Use the gigarouter OpenAI-compatible endpoint with your API key; pass text, image, or audio inputs to the embed endpoint.
We're benchmarking and onboarding BidirLM Omni 2.5B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.