GTE Multilingual Base
Alibaba-NLP/gte-multilingual-base
published Jul 2024 · updated Jul 2025
GTE Multilingual Base is an encoder-only transformer embedding model that generates dense and sparse vectors for multilingual text retrieval and representation tasks.
specs
| Task | Text Embeddings |
| Architecture | Encoder-only transformer |
| Parameters | 305M |
| Max Input Tokens | 8192 |
| Embedding Dimension | 768 (elastic from 128 to 768) |
| Languages | 70+ |
about this model
gte-multilingual-base is an encoder-only multilingual text embedding model that generates dense and sparse vector representations for input text, supporting up to 8,192 tokens and over 70 languages.
Architecture and Capabilities
Trained with an encoder-only transformer architecture, the model delivers a 10x increase in inference speed compared to decode-only LLM-based embedding models of similar size. It supports elastic dense embeddings, allowing the output dimension to be adjusted between 128 and 768 without sacrificing downstream effectiveness, and can also produce sparse token vectors for hybrid retrieval. With 305 million parameters and a native 8,192-token context, it is designed for long-document and multilingual retrieval tasks.
Benchmark Performance
According to the accompanying paper, the text encoder outperforms the same-sized XLM-R and matches the performance of the large-sized BGE-M3 model, achieving better results on long-context retrieval benchmarks. The model achieves state-of-the-art results on multilingual retrieval datasets including MIRACL and MLDR, cross-lingual retrieval on MKQA, and English retrieval on BEIR and LoCo. On the MTEB leaderboard it demonstrates strong performance across English, Chinese, French, and Polish tasks.
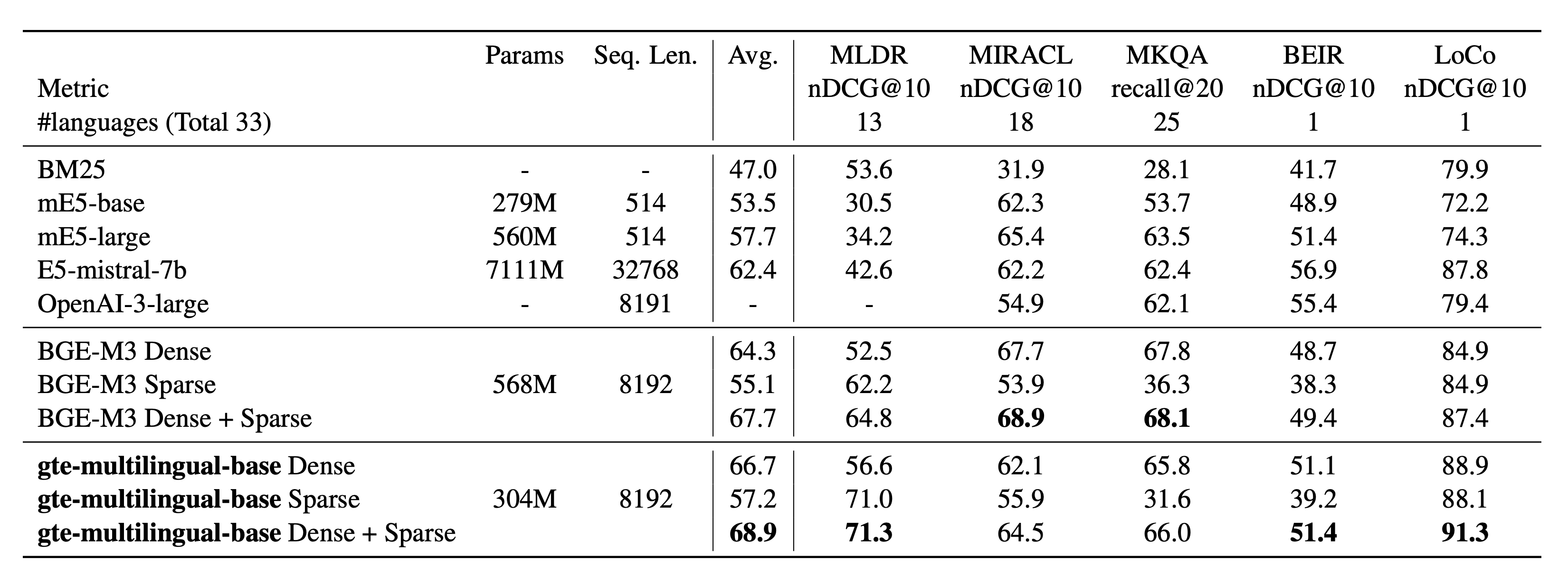
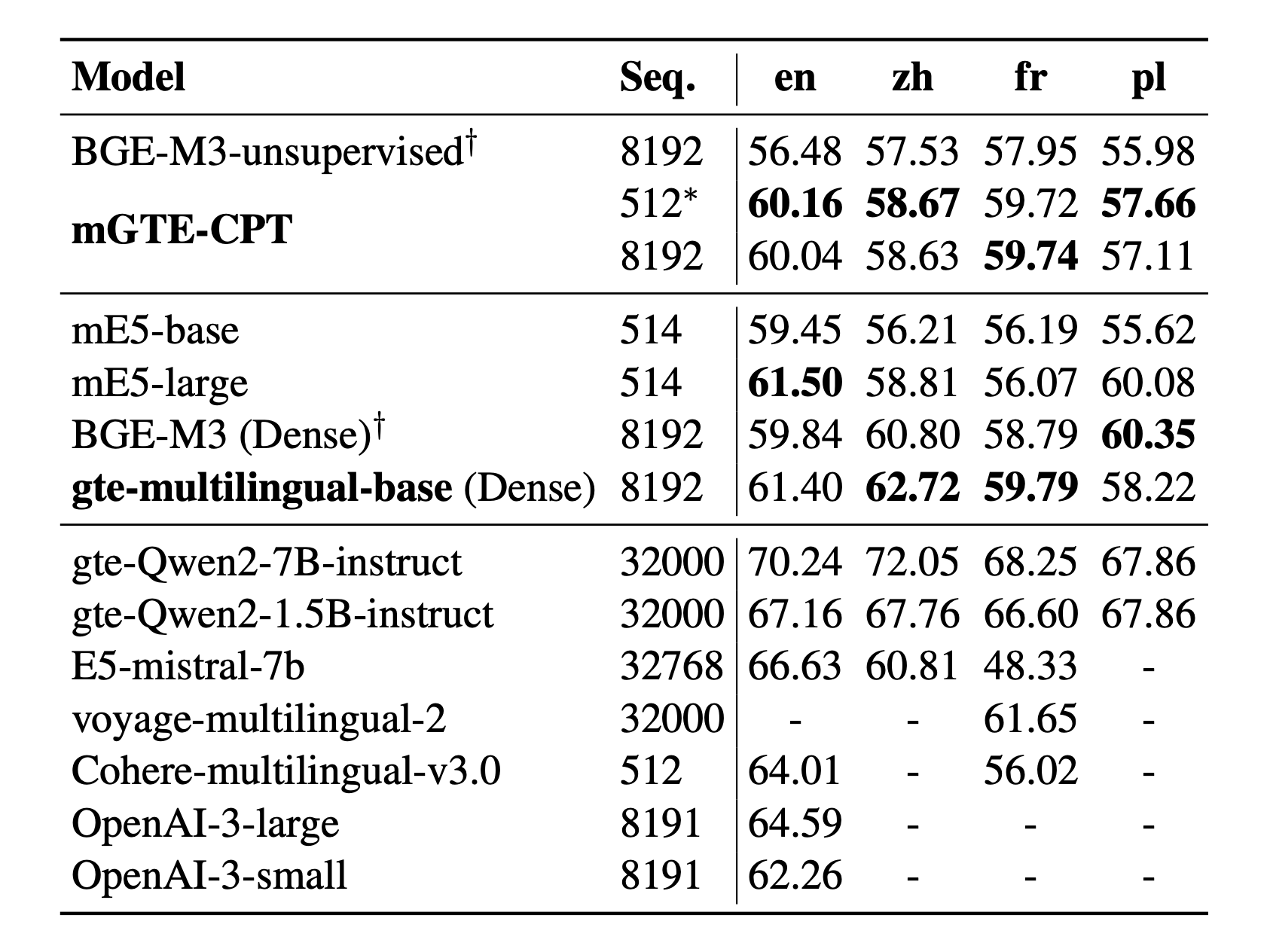
Research Background
The model is introduced in the paper mGTE: Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval (EMNLP 2024 Industry Track). It is part of the GTE family and has been downloaded over 1.2 million times, reflecting its adoption in production and research environments.
best for
- ·Multilingual semantic search across 70+ languages
- ·Long-document retrieval with up to 8192 tokens
- ·Hybrid dense-sparse embedding for efficient storage and retrieval
FAQ
The model supports up to 8192 tokens.
It supports over 70 languages, including both high-resource and low-resource languages.
It outperforms the same-sized XLM-R and matches the performance of large BGE-M3 models while being 10x faster than decoder-based alternatives.
The default dimension is 768, but you can use any dimension from 128 to 768 via elastic dense embedding.
Use the gigarouter OpenAI-compatible endpoint with your API key, sending input texts and specifying the model name.
We're benchmarking and onboarding GTE Multilingual Base as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.