TinyCLIP ViT-8M/16
wkcn/TinyCLIP-ViT-8M-16-Text-3M-YFCC15M
published Dec 2023 · updated May 2024
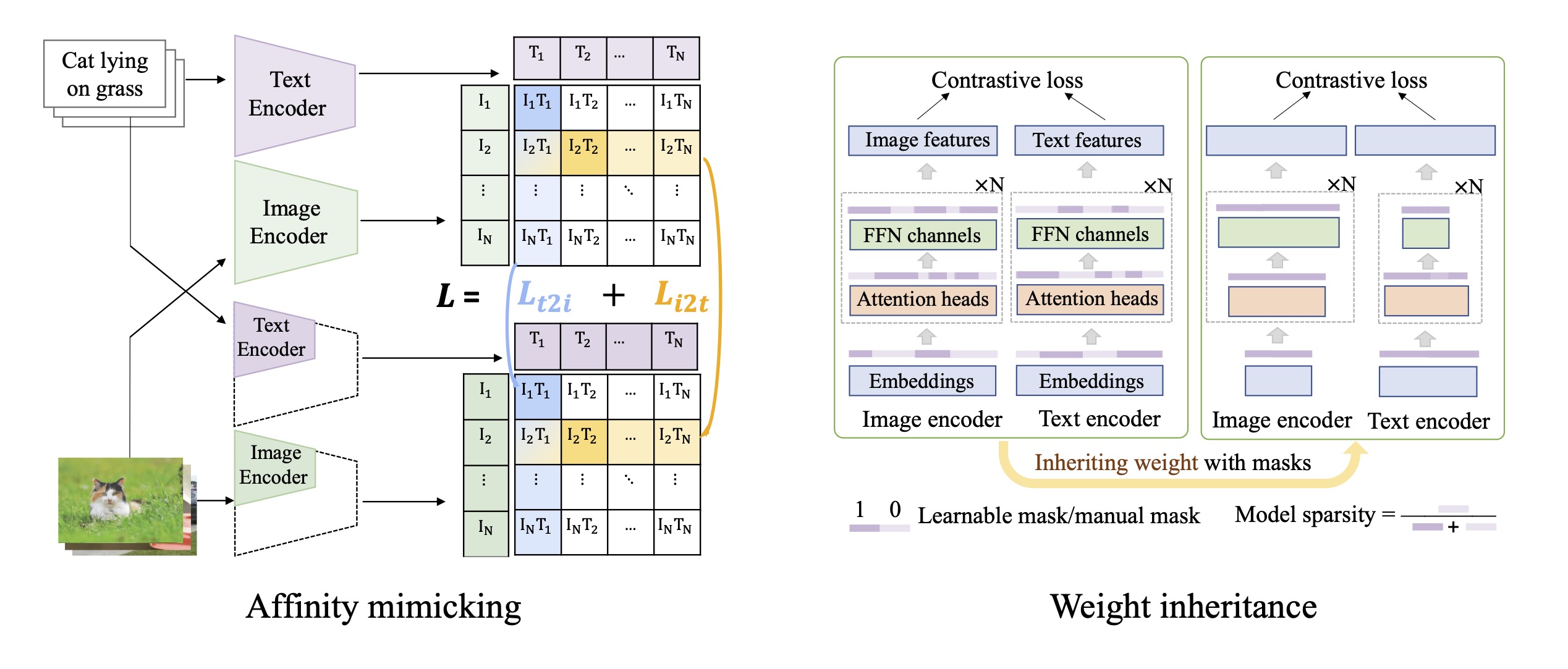
TinyCLIP ViT-8M/16 is a zero-shot-image model that performs image-text similarity and zero-shot classification, distilled from CLIP via affinity mimicking and weight inheritance.
specs
| Task | Zero-shot image classification, image-text similarity |
| Architecture | Vision Transformer (ViT-8M/16) + Text Transformer (3M) |
| Parameters | 11M total (8M vision + 3M text) |
| License | Microsoft (see LICENSE file in repo) |
about this model
Key Strengths
- Extreme parameter efficiency: 8M vision encoder and 3M text encoder
- High throughput: 4,150 pairs/s for rapid inference
- Competitive zero-shot accuracy relative to model size
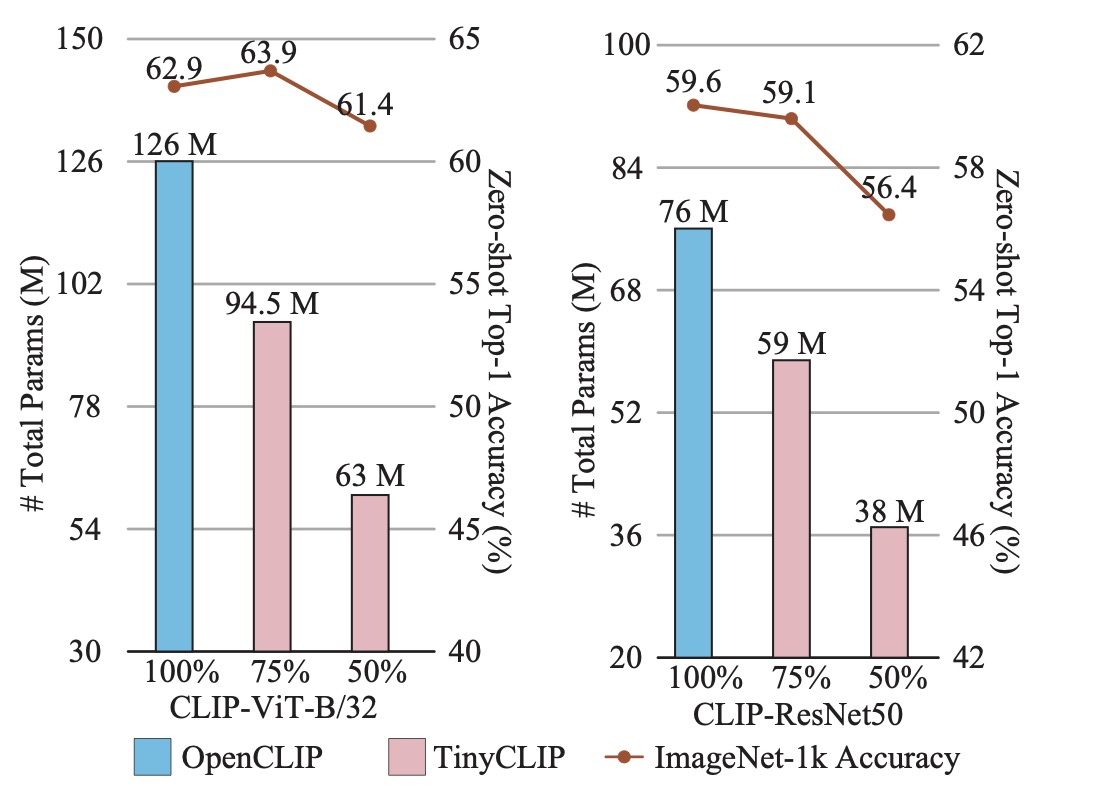
Benchmark Results
| Model Variant | ImageNet Acc@1 (%) | MACs (G) | Throughput (pairs/s) |
|---|---|---|---|
| TinyCLIP ViT-8M/16 Text-3M | 41.1 | 2.0 | 4,150 |
This model is hosted by gigarouter as a managed, OpenAI-compatible API. No local installation or model loading is required; simply call the API endpoint for zero-shot image classification or image-text similarity tasks.
best for
- ·Zero-shot classification of images without fine-tuning
- ·Image-text similarity search and retrieval
- ·Lightweight CLIP model for edge or real-time applications
FAQ
It accepts text prompts and images. Use the CLIPProcessor to tokenize text and preprocess images into tensors.
The model has 11 million parameters total (8M vision encoder + 3M text encoder).
It achieves 41.1% top-1 accuracy on ImageNet zero-shot classification.
Use the OpenAI-compatible endpoint with your API key, sending a request with prompt and image data.
The model is released under a Microsoft license; see the LICENSE file in the official repository.
We're benchmarking and onboarding TinyCLIP ViT-8M/16 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.