GLM-OCR
unsloth/GLM-OCR
published Feb 2026 · updated Feb 2026
GLM-OCR is a multimodal OCR model for complex document understanding, built on the GLM-V encoder–decoder architecture with 0.9B parameters.
specs
| Task | Optical Character Recognition (OCR) / Document Understanding |
| Architecture | GLM-V encoder–decoder with CogViT visual encoder (0.4B) and GLM-0.5B language decoder |
| Parameters | 0.9B |
| Precision | BF16 |
| License | MIT (model); Apache 2.0 (layout analysis component) |
about this model
GLM-OCR is a multimodal OCR model for complex document understanding, built on the GLM-V encoder‑decoder architecture with a 0.4B‑parameter CogViT visual encoder and a 0.5B‑parameter GLM language decoder (0.9B total). It introduces Multi‑Token Prediction (MTP) loss and full‑task reinforcement learning to improve training efficiency, recognition accuracy, and generalization.
Performance
| Benchmark | Score |
|---|---|
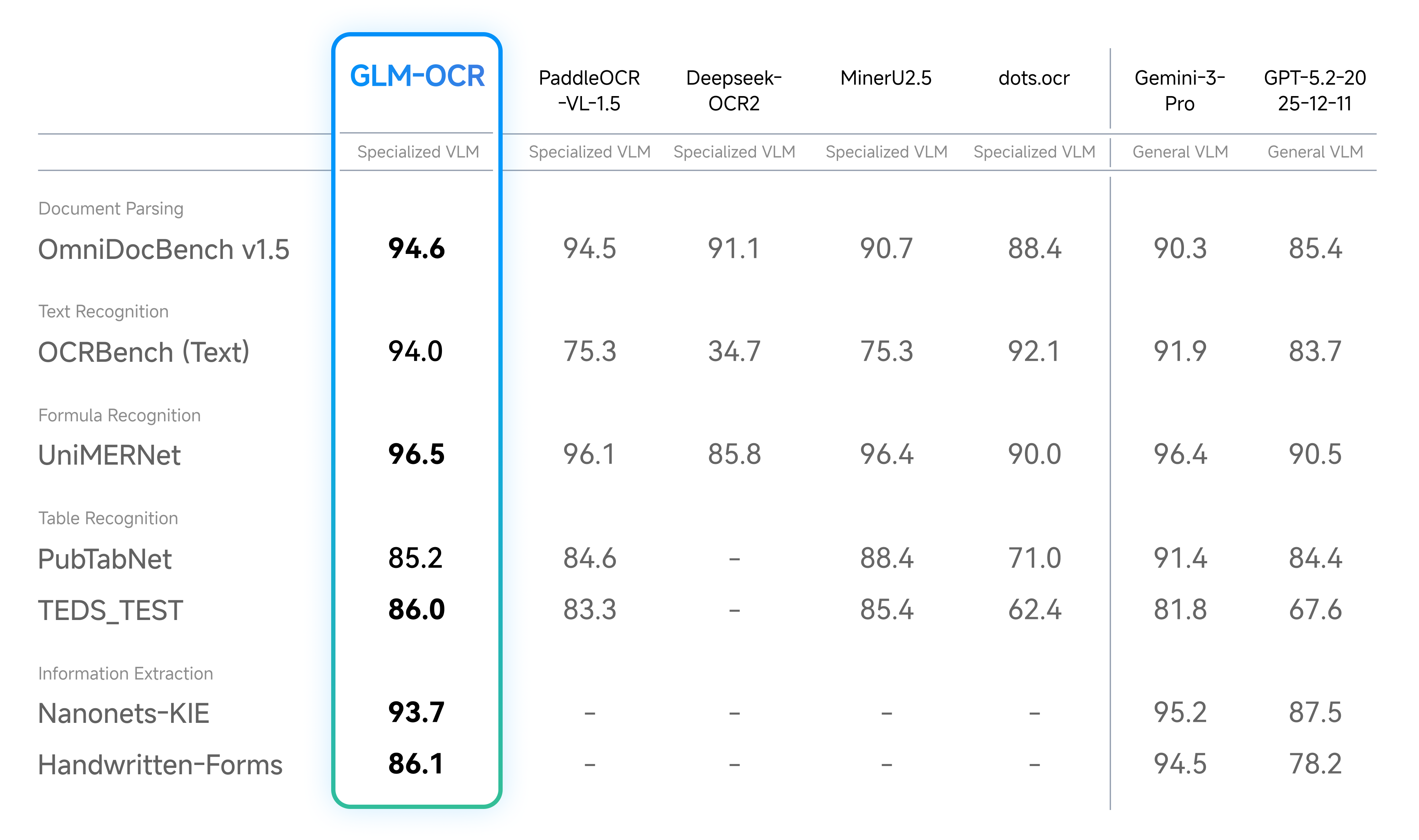
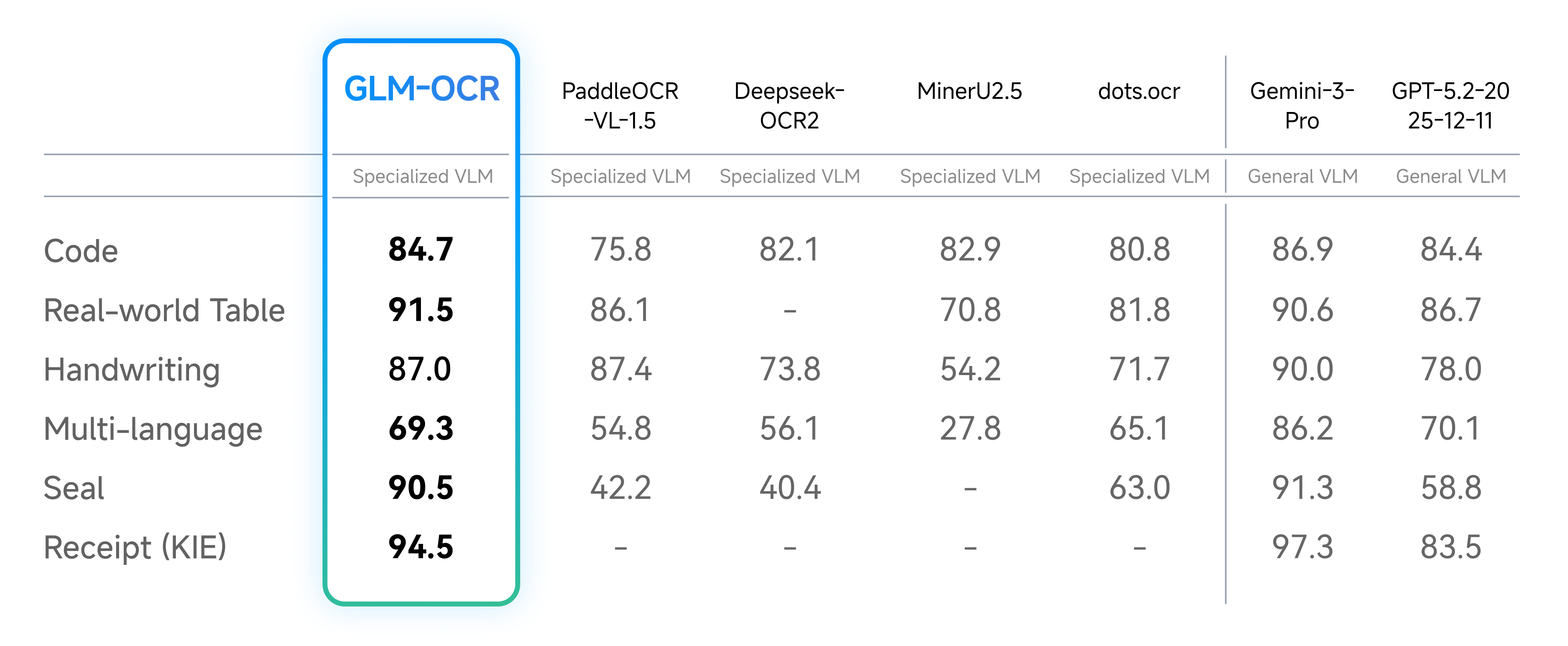
| OmniDocBench V1.5 | 94.62 (#1 overall) |
| Document parsing & information extraction | State‑of‑the‑art across formula, table, and IE tasks |
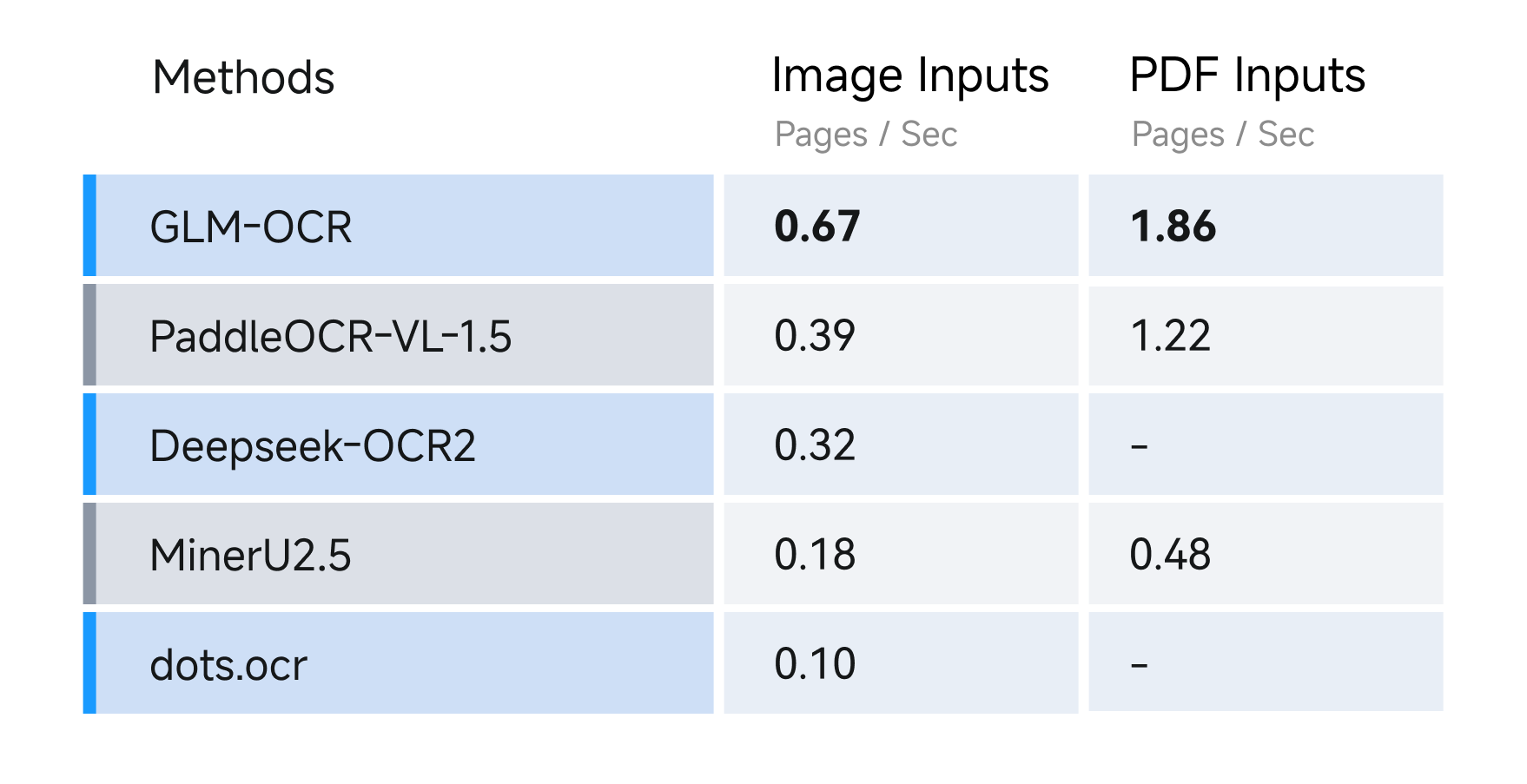
Under single‑replica single‑concurrency testing, GLM-OCR achieves a throughput of 1.86 pages/second for PDF documents and 0.67 images/second for images, significantly outperforming comparable models. Performance approaches that of Gemini‑3‑Pro on document understanding tasks.
Input and Output
- Input: Single image ≤10 MB, PDF ≤50 MB (max 100 pages). Supports Chinese, English, French, Spanish, Russian, German, Japanese, Korean, and other languages.
- Output: Text, image links, or Markdown documents. Supports text recognition, formula recognition, table recognition, and structured information extraction via JSON schema.
Gigarouter hosts GLM-OCR as a managed, OpenAI‑compatible API. Pricing is $0.03 per million tokens, uniform for input and output.
best for
- ·Text recognition and extraction from scanned documents
- ·Table and formula recognition in complex layouts
- ·Structured information extraction (e.g., ID cards, invoices)
- ·Retrieval-Augmented Generation (RAG) document preprocessing
FAQ
It excels at complex document OCR tasks including text recognition, table recognition, formula recognition, and structured information extraction from diverse layouts.
It has a total of 0.9B parameters (0.4B visual encoder + 0.5B language decoder).
The model is released under the MIT License, while the integrated PP-DocLayout-V3 component is under Apache 2.0.
Single images up to 10 MB, or PDF files up to 50 MB with a maximum of 100 pages. Supported languages include Chinese, English, French, Spanish, Russian, German, Japanese, Korean, and others.
Use the gigarouter OpenAI-compatible endpoint with your API key, sending an image or PDF as input and specifying the desired task prompt.
We're benchmarking and onboarding GLM-OCR as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.