Meiki Text Recognition v0
rtr46/meiki.txt.recognition.v0
published Nov 2025 · updated Feb 2026
Meiki Text Recognition v0 is an image-to-text model that performs character-level text recognition for Japanese text, optimized for video games.
specs
| Task | Image-to-text (text recognition) |
| Architecture | D-FINE object detector with MobileNetV4 CNN backbone |
| Input size | 960x32 pixels (resized and padded) |
| Output | Characters with bounding boxes and confidence scores (up to 48 characters) |
| License | LGPL-3.0 |
about this model
meiki.txt.recognition.v0 is an image-to-text model that performs character detection for Japanese text, optimized for video game content. It redefines text recognition as a character detection task using a fine-tuned D-FINE object detector with a MobileNetV4 CNN backbone, outputting individual characters with bounding boxes and confidence scores.
Strengths
The model is designed to be pareto-optimal for Japanese text recognition, offering a superior accuracy-to-latency tradeoff compared to other open-weight alternatives. It is specifically trained on Japanese video games, where it significantly outperforms general-purpose OCR tools such as PaddleOCR or EasyOCR. The architecture is efficient on both CPU and GPU, with the companion detection model achieving typical latencies of ~30 ms (CPU) / ~3 ms (GPU) for the tiny variant.
Benchmarks
The following charts illustrate accuracy versus latency on CPU and GPU for the recognition model:
| CPU | GPU |
|---|---|
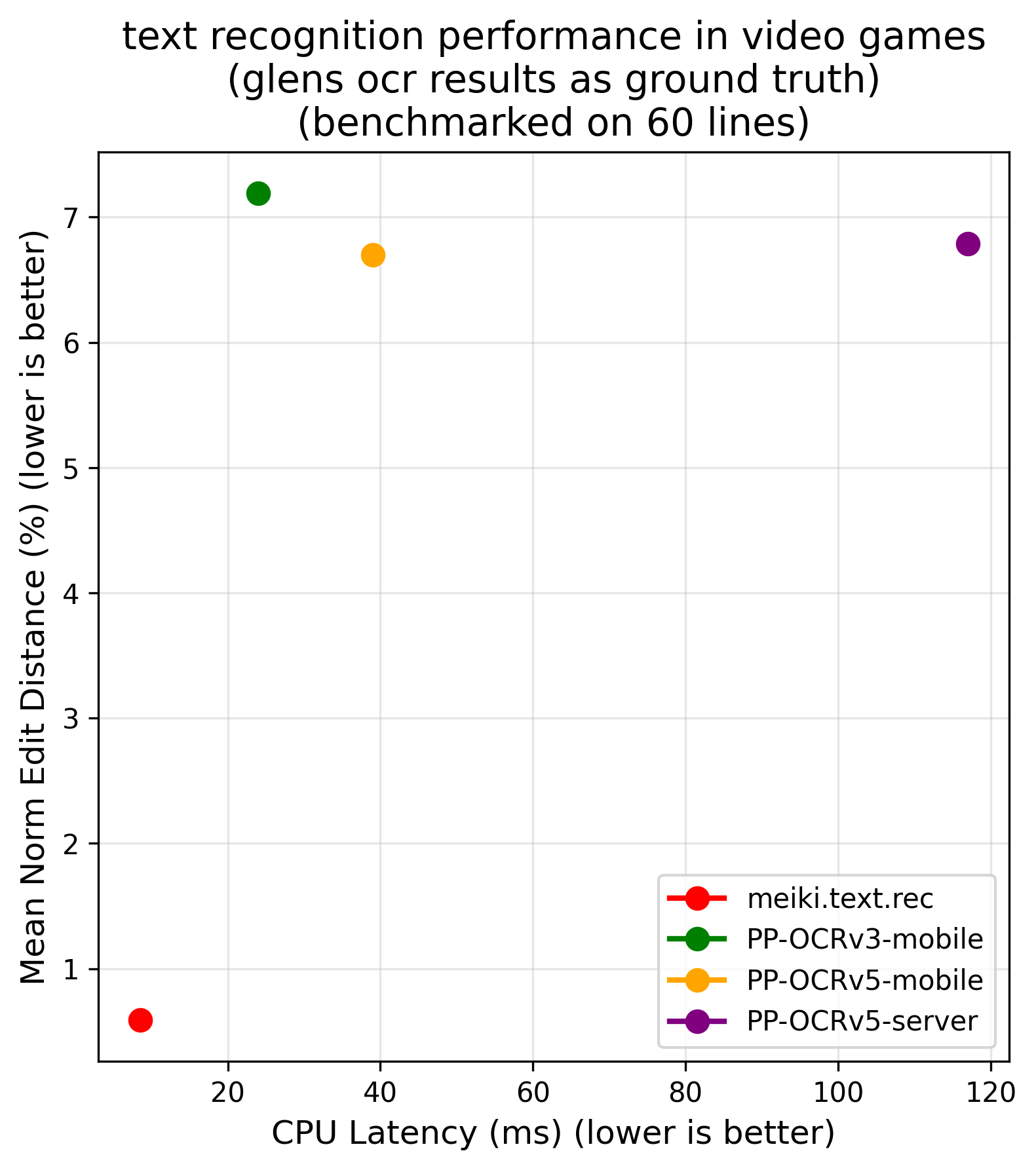 |
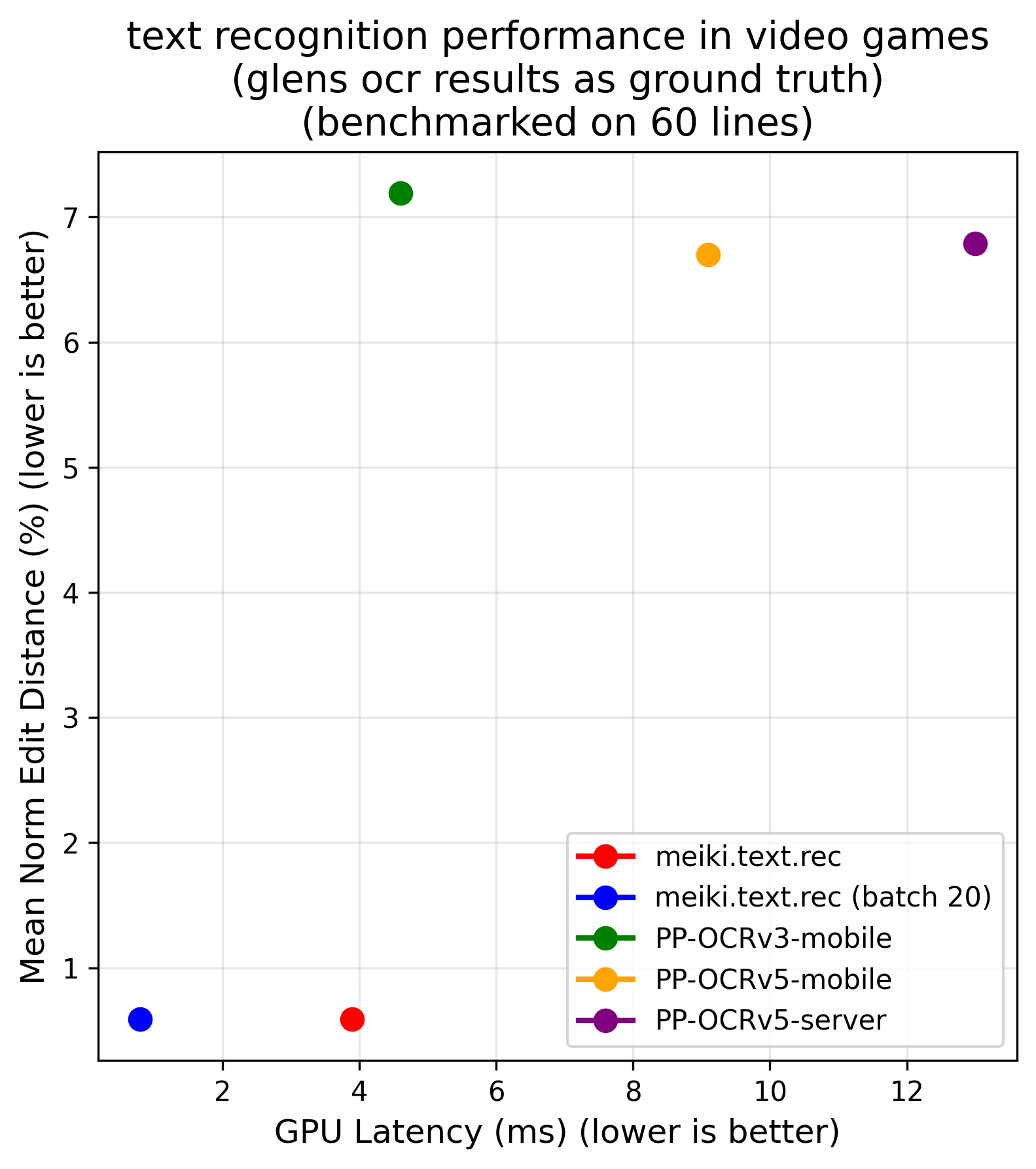 |
Input and output
Input images must be resized and padded to 960x32 pixels. The model detects horizontal text only, with a maximum of 48 characters per inference. Confidence threshold defaults to 0.1 in the inference script, while a value of 0.2 is recommended in the full pipeline CLI. Output is a JSON structure with each character, its bounding box coordinates, and a confidence value. The model is released under LGPL-3.0 (license discrepancy noted with the parent repository's Apache 2.0 badge).
best for
- ·Japanese text recognition from video games
- ·High-speed OCR for horizontal text
- ·Real-time OCR in applications
FAQ
Input images must be resized and padded to 960x32 pixels. Outputs detection results as characters with bounding boxes and confidence.
The model card indicates LGPL-3.0 license.
Up to 48 characters, and it only works on horizontal text.
Use the OpenAI-compatible endpoint with your API key; refer to gigarouter documentation.
The inference script uses a default confidence threshold of 0.1, but the CLI typically uses 0.2.
We're benchmarking and onboarding Meiki Text Recognition v0 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.