OneAlign
q-future/one-align
published Dec 2023 · updated May 2024
OneAlign is a zero-shot-image model that unifies image quality assessment, image aesthetic assessment, and video quality assessment into a single large multi-modality model using discrete text-defined rating levels.
specs
| Task | Image Quality Assessment, Image Aesthetic Assessment, Video Quality Assessment |
| Architecture | mPLUG-Owl2-based LMM |
| Parameters | Not specified in card |
| License | LLaMA-2 license (for commercial use) |
about this model
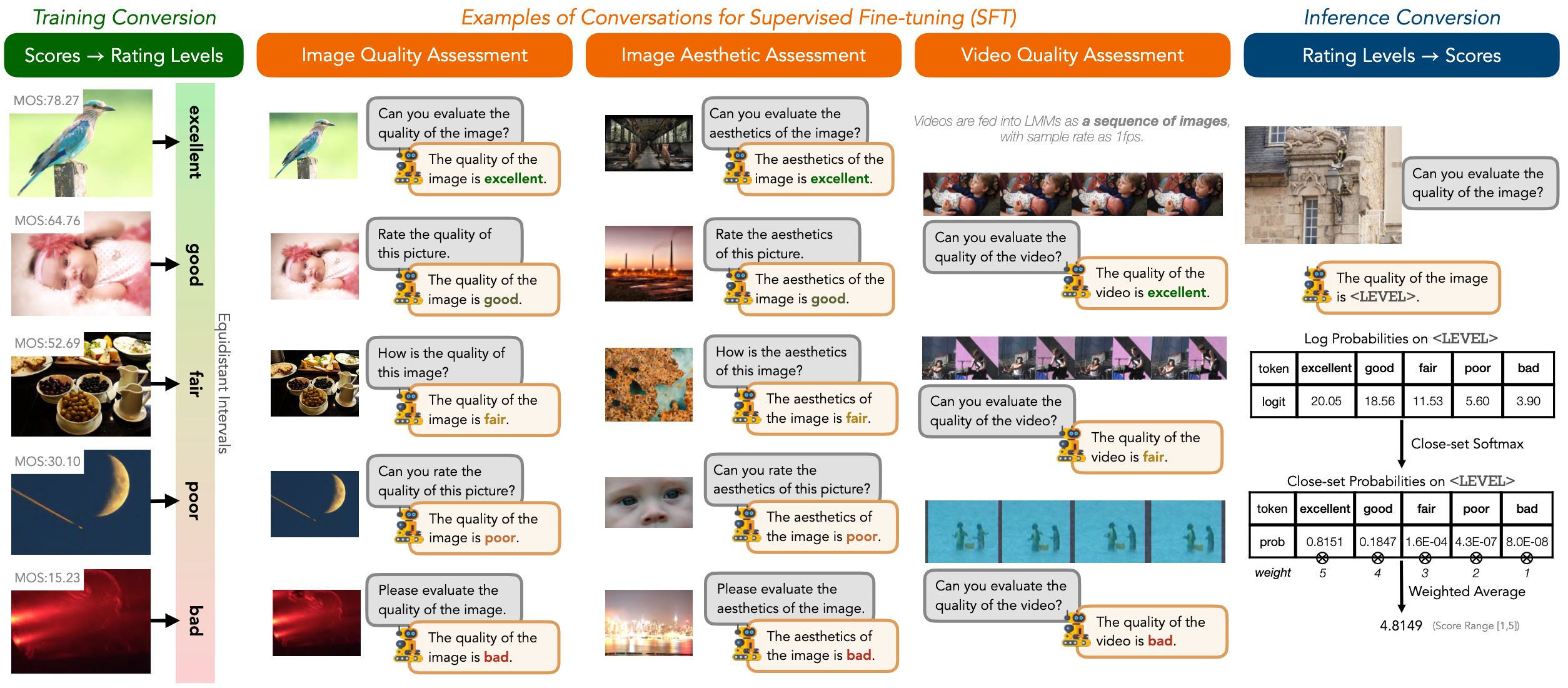
OneAlign is a large multi-modality model for zero-shot visual scoring that unifies image quality assessment (IQA), image aesthetic assessment (IAA), and video quality assessment (VQA) using a discrete-level-based syllabus. Developed by Nanyang Technological University, Shanghai Jiao Tong University, and Sensetime Research, the model is built on the mPLUG-Owl2 architecture and trained on a combination of datasets including KonIQ, SPAQ, KADID, AVA, and LSVQ. Instead of regressing direct scores, it emulates human subjective studies by teaching large multi-modality models (LMMs) with text-defined rating levels, achieving state-of-the-art or competitive performance across all three tasks.
The model scores images and videos on a 1–5 scale. Below is an example input image and the syllabus illustration used during training:

Benchmark Performance
OneAlign achieves leading results on multiple IQA, IAA, and VQA benchmarks. The following table compares its performance against previous state-of-the-art methods across seven IQA datasets, using Spearman/Pearson/Kendall correlations:
| Dataset | KonIQ (NR-IQA, seen) | SPAQ (NR-IQA, seen) | KADID (FR-IQA, seen) | LIVE-C (NR-IQA, unseen) | LIVE (FR-IQA, unseen) | CSIQ (FR-IQA, unseen) | AGIQA (AIGC, unseen) |
|---|---|---|---|---|---|---|---|
| Previous SOTA | 0.916/0.928 (MUSIQ) | 0.922/0.919 (LIQE) | 0.934/0.937 (CONTRIQUE) | NA | NA | NA | NA |
| OneAlign | 0.941/0.950/0.791 | 0.932/0.935/0.766 | 0.941/0.942/0.791 | 0.881/0.894/0.699 | 0.887/0.856/0.699 | 0.881/0.906/0.699 | 0.801/0.838/0.602 |
On the AVA_test aesthetic benchmark, OneAlign achieves a Spearman correlation of 0.823 and Pearson of 0.819, surpassing prior methods. For video quality assessment, it sets new state-of-the-art on LSVQ_test (0.886/0.886), LSVQ_1080p (0.803/0.837), KoNViD-1k (0.876/0.888), and MaxWell_test (0.781/0.786).
Users must comply with the LLaMA-2 license when using this model commercially. The model is hosted as a managed API on gigarouter, requiring no local installation.
best for
- ·Scoring image quality on a 1-5 scale
- ·Assessing image aesthetics
- ·Evaluating video quality
FAQ
It supports image quality assessment (IQA), image aesthetic assessment (IAA), and video quality assessment (VQA) in a single model.
Use the gigarouter OpenAI-compatible endpoint with your API key, passing an image or video input and specifying the task (quality or aesthetics).
The model outputs a score in the range [1, 5], where higher is better.
You must comply with LLaMA-2 licenses if using the checkpoints commercially.
OneAlign unifies IQA, IAA, and VQA into one model, achieving state-of-the-art results across multiple benchmarks.
We're benchmarking and onboarding OneAlign as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.