ViT GPT-2 Image Captioning
nlpconnect/vit-gpt2-image-captioning
published Mar 2022 · updated Feb 2023
ViT GPT-2 Image Captioning is an image-to-text model that generates captions for images using a Vision Transformer encoder and a GPT-2 decoder.
specs
| Task | Image-to-Text (Image Captioning) |
| Architecture | Vision Encoder-Decoder (ViT encoder + GPT-2 decoder) |
| Dataset | COCO 2017 |
about this model
nlpconnect/vit-gpt2-image-captioning is an image-to-text model that generates captions for input images using a Vision Transformer (ViT) encoder and a GPT-2 decoder. The encoder is google/vit-base-patch16-224-in21k and the decoder is GPT-2. The model was fine-tuned on the COCO 2017 dataset as a proof-of-concept for the FlaxVisionEncoderDecoder framework; it is not a state-of-the-art model and no benchmark scores (e.g., BLEU, CIDEr) are publicly available.
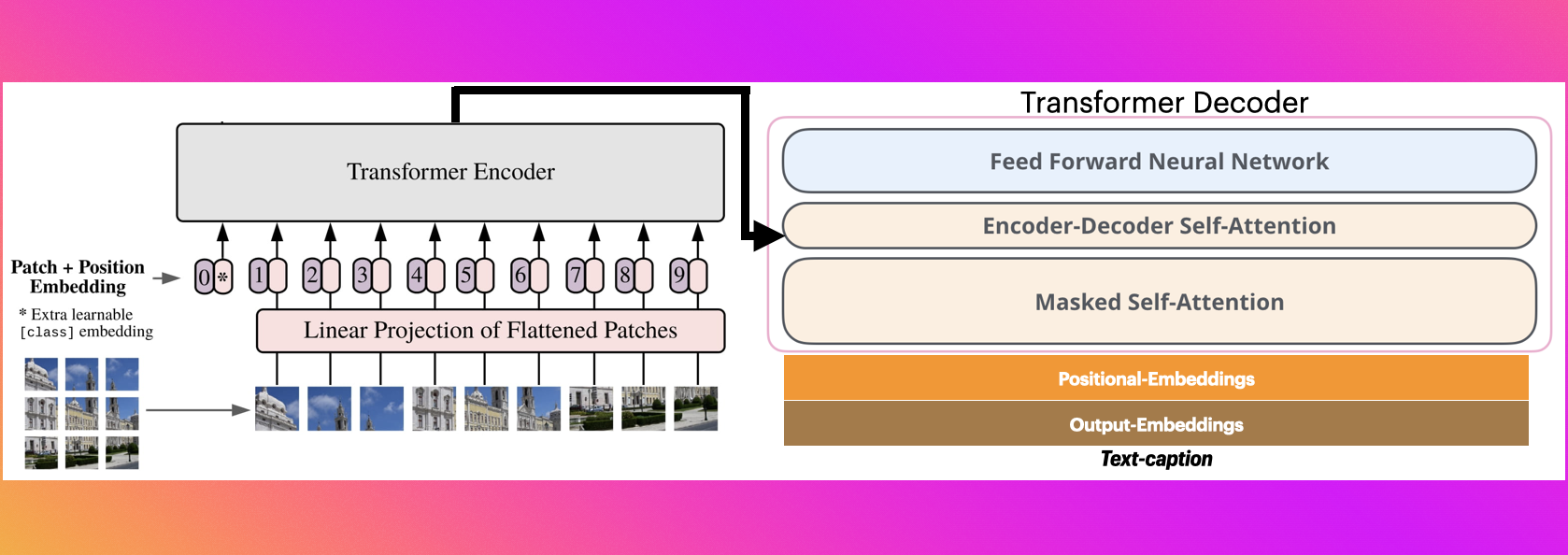
Generation parameters used in the reference implementation: max_length=16 and num_beams=4. Sample outputs from the model card show a tendency toward repetitive captions (e.g., "a woman in a hospital bed with a woman in a hospital bed"), which may indicate a limitation in generation quality. The model weights have approximately 4,900 all-time downloads on Hugging Face.
Gigarouter hosts this model as a managed, OpenAI-compatible API, allowing developers to integrate image captioning without managing infrastructure or dependencies.
best for
- ·Generating descriptive captions for user-uploaded images
- ·Assisting visually impaired users with image descriptions
- ·Automating image metadata for content management systems
FAQ
It uses a Vision Transformer (ViT) as the encoder and GPT-2 as the decoder, forming a VisionEncoderDecoderModel.
It was fine-tuned on the COCO 2017 dataset for image captioning.
No, it is a proof-of-concept fine-tuned with the FlaxVisionEncoderDecoder framework and is not intended to be state-of-the-art.
Send a POST request to the gigarouter OpenAI-compatible endpoint with your API key and an image URL or base64 data; the response will contain the generated caption.
Input is an image (URL or base64), output is a plain text caption string.
We're benchmarking and onboarding ViT GPT-2 Image Captioning as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.