Donut Base
naver-clova-ix/donut-base
published Jul 2022 · updated Aug 2022
Donut Base is an image-to-text model that performs OCR-free document understanding using a Swin Transformer encoder and a BART decoder.
specs
| Task | Image-to-Text / Document Understanding |
| Architecture | Swin Transformer encoder + BART decoder |
about this model
Donut (base-sized) is an image-to-text model that performs OCR-free document understanding using a vision encoder (Swin Transformer) and a text decoder (BART). Given an image, the encoder produces a sequence of embeddings, and the decoder autoregressively generates text conditioned on those embeddings.
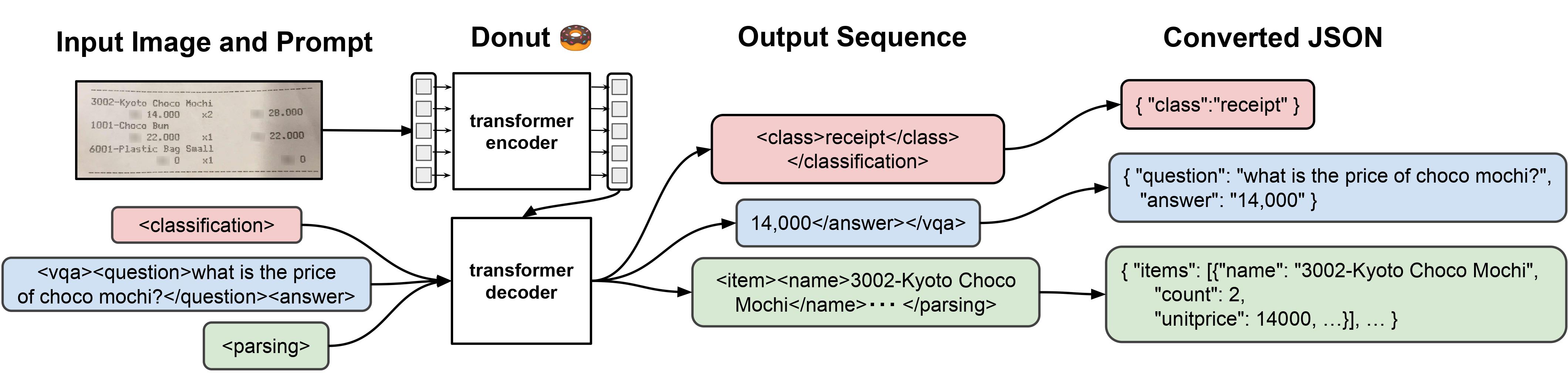
Introduced in the paper OCR-free Document Understanding Transformer (ECCV 2022), Donut eliminates the need for external OCR engines, reducing computational cost, increasing flexibility across languages and document types, and avoiding OCR error propagation. According to the paper, Donut achieves state-of-the-art results on multiple visual document understanding (VDU) benchmarks in both speed and accuracy.
This pre-trained base model is designed to be fine-tuned on downstream tasks such as document image classification or information extraction (document parsing). When hosted via gigarouter’s API, it provides a foundation for building custom document understanding pipelines without managing infrastructure.
best for
- ·Fine-tuning on document image classification
- ·Fine-tuning on document parsing (information extraction)
- ·OCR-free document understanding research and development
FAQ
Donut eliminates the need for external OCR engines, reducing computational cost and avoiding error propagation.
This is a pre-trained only model; it must be fine-tuned on a downstream task such as document classification or parsing.
Input: an image (e.g., a document scan). Output: generated text (e.g., structured JSON for parsing, or a label for classification).
Use the OpenAI-compatible endpoint with your API key; send the image as a base64-encoded string in the request.
We're benchmarking and onboarding Donut Base as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.