Voxtral Mini 4B Realtime 2602
mistralai/Voxtral-Mini-4B-Realtime-2602
published Jan 2026 · updated Mar 2026
Voxtral Mini 4B Realtime 2602 is a multilingual, realtime speech-transcription model that achieves accuracy comparable to offline systems with sub-500ms latency.
specs
| Task | Automatic Speech Recognition (ASR) / Real-Time Transcription |
| Architecture | Natively streaming causal audio encoder (970M) + language model (3.4B) with sliding window attention |
| Parameters | 4B (BF16) |
| Languages | 13 languages (Arabic, German, English, Spanish, French, Hindi, Italian, Dutch, Portuguese, Chinese, Japanese, Korean, Russian) |
| License | Apache 2.0 |
about this model
Voxtral Mini 4B Realtime 2602 is a realtime automatic speech recognition (ASR) model hosted on gigarouter that transcribes speech in 13 languages with sub-500ms latency, matching offline quality at configurable delays.
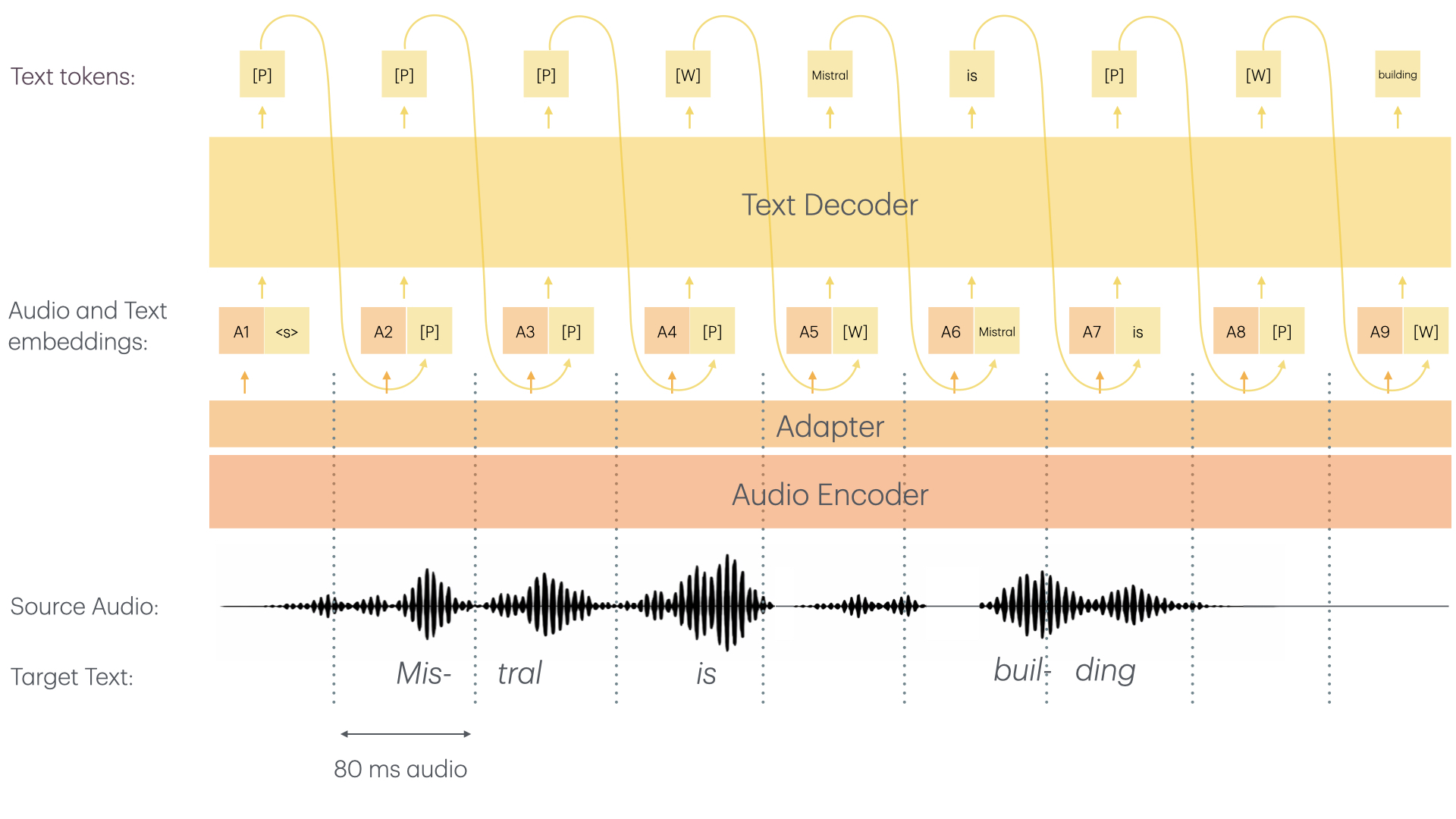
Architecture and Streaming
The model uses a custom causal audio encoder (≈970M parameters) and a language model backbone (≈3.4B parameters) built on the Delayed Streams Modeling framework with Ada RMS-Norm. Sliding window attention enables continuous streaming of arbitrary length. Transcription delay is configurable from 80ms to 2400ms; at 480ms delay the model achieves word error rates on par with leading offline open-source systems and realtime APIs, including Whisper.
Benchmark Results
On the Fleurs dataset (13 languages), the model at 480ms delay achieves an average WER of 8.72%, compared to 5.90% for the offline Voxtral Mini Transcribe 2.0. Language-specific results:
| Model | Delay | AVG | Arabic | German | English | Spanish | French | Hindi | Italian | Dutch | Portuguese | Chinese | Japanese | Korean | Russian |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Voxtral Mini Transcribe 2.0 | Offline | 5.90% | 13.54% | 3.54% | 3.32% | 2.63% | 4.32% | 10.33% | 2.17% | 4.78% | 3.56% | 7.30% | 4.14% | 12.29% | 4.75% |
| Voxtral Mini 4B Realtime 2602 | 480ms | 8.72% | 22.53% | 6.19% | 4.90% | 3.31% | 6.42% | 12.88% | 3.27% | 7.07% | 5.03% | 10.45% | 9.59% | 15.74% | 6.02% |
On long-form English benchmarks (Meanwhile, E-21, E-22, TEDLIUM), the model at 480ms produces WERs of 5.05%, 10.23%, 12.30%, and 3.17% respectively—within 0.3–1% of the offline model. Short-form English results (CHiME-4, GigaSpeech, AMI IHM, SwitchBoard) also remain within 0.5% of offline performance.
For further details, see the technical report, blog post, and interactive demo.
The model is released under Apache-2.0 license and runs in BF16. Throughput exceeds 12.5 tokens/second on a single GPU with ≥16GB memory.
best for
- ·Real-time meeting transcription
- ·Live subtitling for broadcasts and events
- ·Voice assistant with low-latency speech understanding
FAQ
It achieves sub-500ms realtime transcription, with configurable delays from 80ms to 2.4s. A 480ms delay is recommended as the sweet spot for accuracy and latency.
At a 480ms delay, it matches the performance of Whisper, the leading offline transcription system, while operating in realtime.
It supports 13 languages: Arabic, German, English, Spanish, French, Hindi, Italian, Dutch, Portuguese, Chinese, Japanese, Korean, and Russian.
Apache 2.0, allowing both research and commercial use.
Use the gigarouter OpenAI-compatible endpoint with an API key, sending audio via WebSocket for realtime streaming transcription.
We're benchmarking and onboarding Voxtral Mini 4B Realtime 2602 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.