VibeVoice ASR
microsoft/VibeVoice-ASR-HF
published Mar 2026 · updated Mar 2026
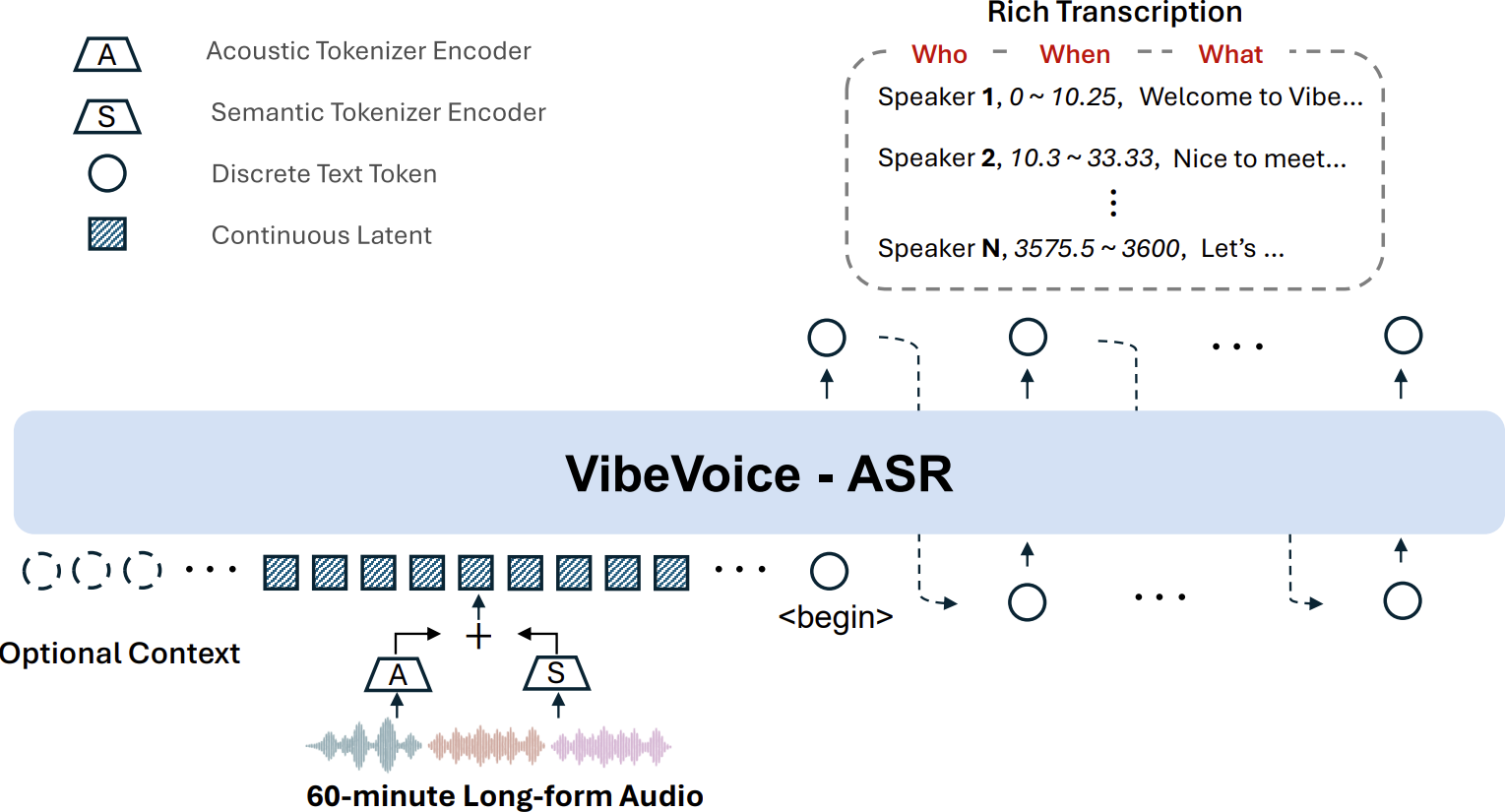
VibeVoice ASR is a unified speech-to-text model that transcribes up to 60 minutes of long-form audio in a single pass, generating structured output with speaker diarization, timestamps, and content in over 50 languages.
specs
| Task | Automatic Speech Recognition (ASR) with speaker diarization and timestamping |
| Architecture | VibeVoice-ASR-7B |
| Parameters | 7 billion |
| License | Not specified in the model card |
about this model
VibeVoice-ASR is a unified speech-to-text model that processes up to 60 minutes of long-form audio in a single pass and generates structured transcriptions identifying who spoke what and when, with support for over 50 languages, code-switching, and customized hotwords.
Key Capabilities
- Single-pass processing of 60-minute audio — maintains global context and consistent speaker tracking across the full duration.
- Rich transcription output — jointly performs automatic speech recognition (ASR), speaker diarization, and timestamping in one end-to-end generation step.
- Customized hotwords — users can supply domain-specific terms or names (e.g., proper nouns, technical jargon) to guide recognition and improve accuracy.
- Multilingual and code-switching support — natively handles over 50 languages without requiring explicit language setting; switches seamlessly within and across utterances.
Benchmark Performance
The model (VibeVoice-ASR-7B, 7 billion parameters) uses a continuous speech tokenizer operating at a 7.5 Hz frame rate. Representative results on public datasets:
| Dataset | Language | DER (%) | WER (%) |
|---|---|---|---|
| MLC-Challenge (average) | Multilingual | 3.42 | 12.07 |
| AISHELL-4 | Chinese | — | 21.40 |
| AMI-IHM | English | — | 18.81 |
DER = diarization error rate, WER = word error rate. Full results are in the technical report.
Additional Capabilities
- Prompt-based context injection — provide textual context (e.g., a topic summary) to improve accuracy on domain-specific terminology and polyphonic character disambiguation.
- Batch inference — process multiple audio files concurrently.
- vLLM inference support — enables faster decoding when deployed with vLLM.
- Fine-tuning — LoRA fine-tuning code is publicly available for adapting the model to custom domains.
best for
- ·Transcribing long meetings and podcasts up to 60 minutes in a single pass
- ·Multi-speaker diarization with speaker labels and timestamps
- ·Domain-specific transcription with custom hotwords and context prompts
FAQ
It can process up to 60 minutes of continuous audio within a 64K token length.
Yes, it jointly performs ASR, speaker diarization, and timestamping, outputting who said what and when.
It supports over 50 languages and handles code-switching natively without requiring an explicit language setting.
You can pass a prompt string to the apply_transcription_request method to guide recognition on domain-specific terms.
Use the gigarouter OpenAI-compatible endpoint with your API key to send audio and receive structured transcriptions.
We're benchmarking and onboarding VibeVoice ASR as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.