Phi-4 Multimodal Instruct
microsoft/Phi-4-multimodal-instruct
published Feb 2025 · updated Dec 2025
Phi-4 Multimodal Instruct is a lightweight open multimodal foundation model that processes text, image, and audio inputs to generate text outputs, supporting 128K token context length and multiple languages.
specs
| Task | Automatic speech recognition, speech translation, speech summarization, speech QA, image understanding, OCR, chart/table understanding, multi-image summarization |
| Architecture | Mixture-of-LoRAs with modality-specific adapters and routers over a frozen 3.8B-parameter language model |
| Parameters | 3.8 billion (base language model); speech/audio LoRA adapters add 460 million parameters |
about this model
Speech Recognition Performance
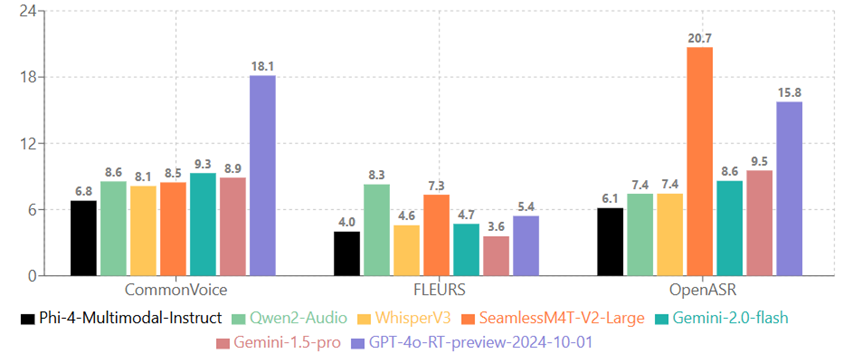
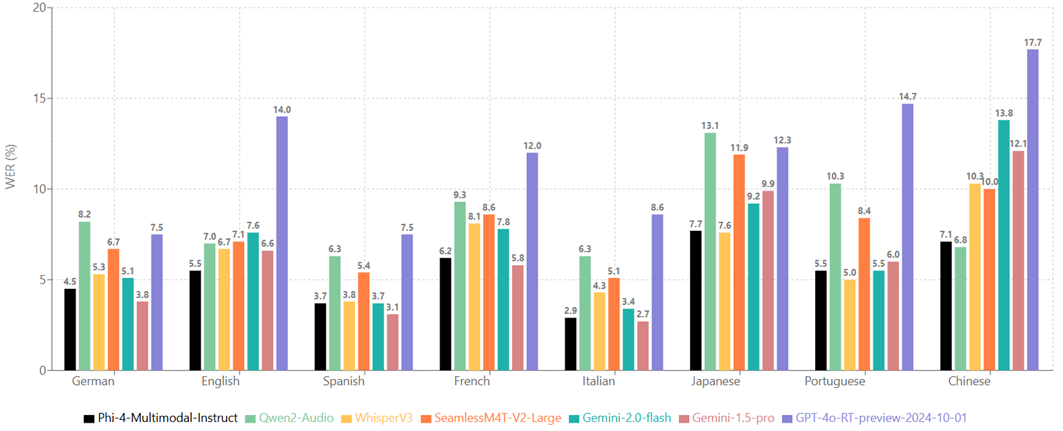
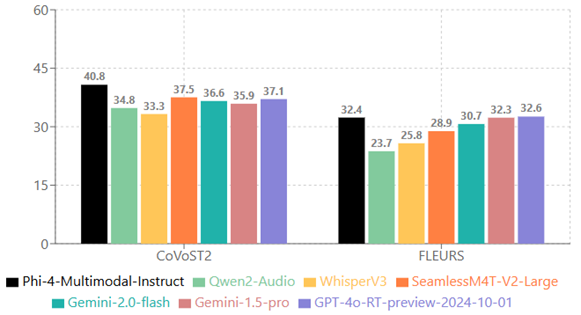
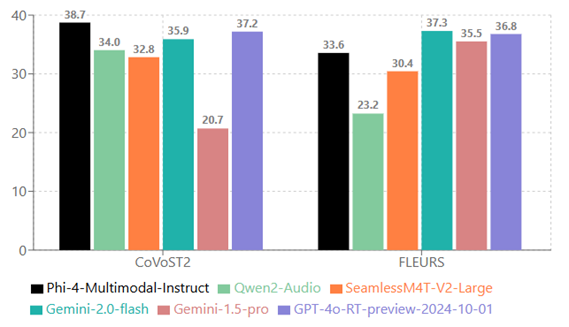
On the HuggingFace OpenASR leaderboard, Phi-4-multimodal-instruct ranked first with a word error rate of 6.14% (as of March 2025), surpassing expert models such as WhisperV3 and SeamlessM4T-v2-Large. It also performs speech translation (bidirectional between English and seven other languages) and speech summarization, with summarization quality close to GPT‑4o.
Vision-Speech Task Performance
When processing image and audio inputs together, the model achieves strong results on vision-speech benchmarks:
| Benchmark | Phi-4-multimodal-instruct | InternOmni-7B | Gemini-2.0-Flash-Lite | Gemini-2.0-Flash | Gemini-1.5-Pro |
|---|---|---|---|---|---|
| s_AI2D | 68.9 | 53.9 | 62.0 | 69.4 | 67.7 |
| s_ChartQA | 69.0 | 56.1 | 35.5 | 51.3 | 46.9 |
| s_DocVQA | 87.3 | 79.9 | 76.0 | 80.3 | 78.2 |
| s_InfoVQA | 63.7 | 60.3 | 59.4 | 63.6 | 66.1 |
| Average | 72.2 | 62.6 | 58.2 | 66.2 | 64.7 |
The model is available via gigarouter’s OpenAI-compatible API, requiring no local setup. Benchmark scores and additional technical details are documented in the Phi-4-Multimodal technical report.
best for
- ·Real-time speech recognition and translation in multilingual customer service applications
- ·Multimodal document understanding combining images, charts, and spoken queries
- ·Memory-constrained or latency-sensitive environments requiring strong reasoning and function calling
FAQ
It accepts text, image, and audio inputs, and generates text outputs. It supports vision+language, vision+speech, and speech/audio-only inference modes.
The model supports a 128K token context length and uses an expanded vocabulary of 200K tokens for better multilingual support.
Phi-4 Multimodal surpasses WhisperV3 on automatic speech recognition and speech translation benchmarks, ranking first on the Hugging Face OpenASR leaderboard with a mean WER of 6.02%.
The model is released under the MIT license.
Use the gigarouter OpenAI-compatible endpoint with your API key to send text, image, or audio inputs and receive text responses.
We're benchmarking and onboarding Phi-4 Multimodal Instruct as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.