CLIP ConvNeXt Base W AugReg
laion/CLIP-convnext_base_w-laion2B-s13B-b82K-augreg
published Jan 2023 · updated Apr 2023
CLIP ConvNeXt Base W AugReg is a zero-shot-image model that performs zero-shot image classification and image-text retrieval using a ConvNeXt-Base vision tower trained on LAION-2B.
specs
| Task | Zero-Shot Image Classification |
| Architecture | ConvNeXt-Base image tower (wide embedding dim) + text tower similar to RN50x4 (depth 12, embed dim 640) |
| License | MIT |
| Resolution | 256x256 |
| Training Data | LAION-2B (2 billion English image-text pairs) |
about this model
CLIP-convnext_base_w-laion2B-s13B-b82K-augreg is a zero-shot image classification model that combines a ConvNeXt-Base (wide embed dim) image tower with the same text tower used in OpenAI's RN50x4 model, trained on the LAION-2B dataset using OpenCLIP. It is hosted on gigarouter as a managed, OpenAI-compatible API.
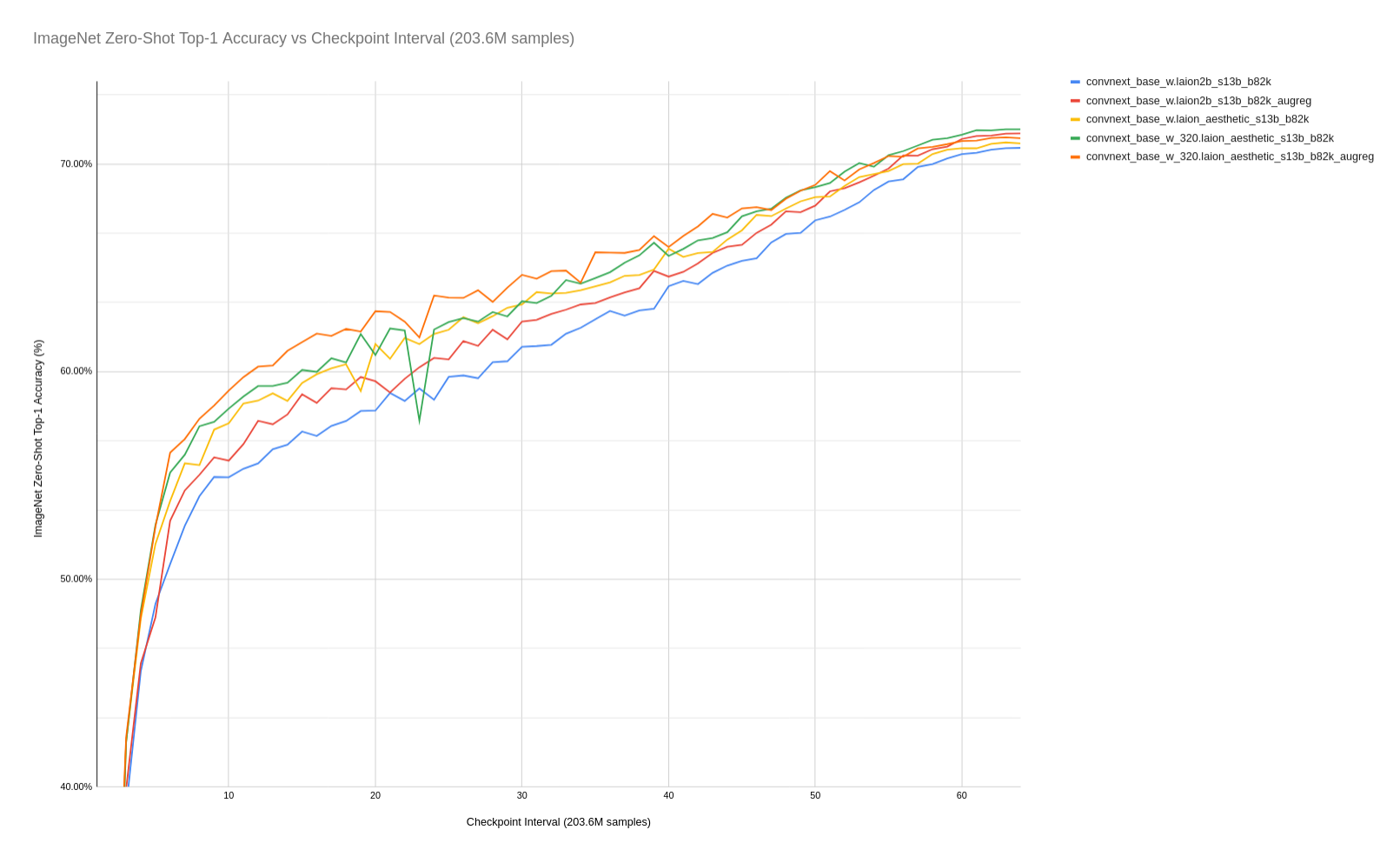
The model was trained for 13 billion samples at 256x256 resolution and achieves 71.5% zero-shot top-1 accuracy on ImageNet-1k. It is the first known ConvNeXt CLIP model trained at scale in the range of CLIP ViT-B/16 and RN50x4 models, and the first to explore increased augmentation and regularization for the image tower via random resize crop (RRC 0.33–1.0), random erasing (RE probability 0.35), and stochastic depth (SD probability 0.1). Compared to ViT-B/16 (68.1% at 13B samples), the ConvNeXt backbone suggests greater sample efficiency at this scale of model.
Early evaluations indicate that the augreg variant generalizes better across resolutions. When evaluated at 384x384, the 320x320 LAION-Aesthetic augreg model improves to 72.2% (vs. 71.0% for the non-augreg version). Benchmark results on VTAB+ and retrieval datasets (COCO, Flickr) are viewable in the LAION CLIP Benchmark suite.
| Model Variant | Dataset | Resolution | AugReg | ImageNet Zero-Shot (%) |
|---|---|---|---|---|
| convnext_base_w (no augreg) | LAION-2B | 256x256 | RRC (0.9, 1.0) | 70.8 |
| convnext_base_w (augreg) | LAION-2B | 256x256 | RRC (0.33, 1.0), RE (0.35), SD (0.1) | 71.5 |
| convnext_base_w (aesthetic) | LAION-Aesthetic | 256x256 | RRC (0.9, 1.0) | 71.0 |
| convnext_base_w_320 (aesthetic) | LAION-Aesthetic | 320x320 | RRC (0.9, 1.0) | 71.7 |
| convnext_base_w_320 (aesthetic, augreg) | LAION-Aesthetic | 320x320 | RRC (0.33, 1.0), RE (0.35), SD (0.1) | 71.3 |
Released under the MIT license, the model was created on 2023-01-10 and is tagged for the Zero-Shot Image Classification pipeline.
best for
- ·Zero-shot image classification with arbitrary class labels
- ·Image and text retrieval (e.g., search relevant images from a text query)
- ·Fine-tuning for custom image classification tasks
FAQ
It excels at zero-shot image classification and image-text retrieval without requiring task-specific training data.
It roughly matches the FLOPs and activation counts of RN50x4 models, making it efficient while achieving over 71% ImageNet zero-shot accuracy.
The model is released under the MIT license, allowing free use, modification, and distribution.
Input: an image (any format) and one or more text prompts. Output: cosine similarity scores between the image and each text prompt.
Use the OpenAI-compatible endpoint with your API key. Pass an image URL or base64-encoded image along with text inputs to get similarity scores.
We're benchmarking and onboarding CLIP ConvNeXt Base W AugReg as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.