ALIGN Base
kakaobrain/align-base
published Feb 2023 · updated Mar 2023
ALIGN Base is a zero-shot image classification and multi-modal embedding model that uses a dual-encoder architecture with EfficientNet and BERT to align visual and text representations via contrastive learning.
specs
| Task | Zero-Shot Image Classification & Multi-Modal Embedding Retrieval |
| Architecture | Dual-encoder: EfficientNet (vision) + BERT (text) |
| Parameters | Not specified in the card |
| License | Not specified in the card |
about this model
ALIGN (base model) is a zero-shot image classification and multi-modal embedding model that uses a dual-encoder architecture with EfficientNet as its vision encoder and BERT as its text encoder, trained with contrastive learning to align visual and language representations.
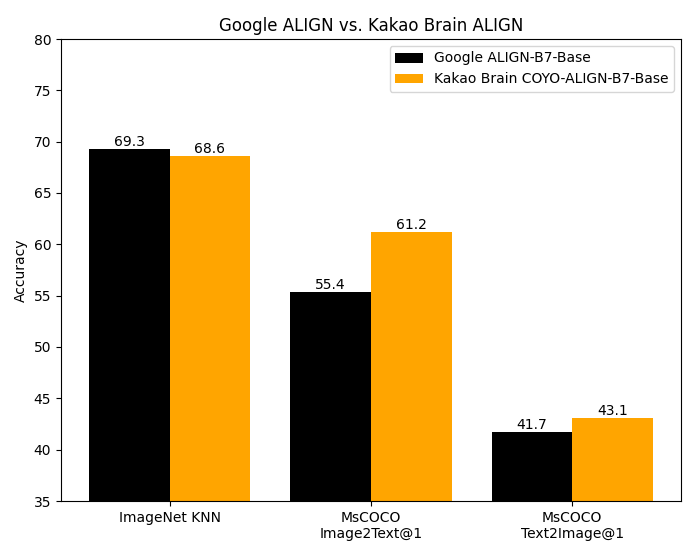
Developed by Kakao Brain, this model is a reproduction of Google's ALIGN architecture, trained on the open-source COYO-700M dataset rather than Google's non-public 1.8 billion image-text pairs. Despite training on a smaller dataset, Kakao Brain's ALIGN achieves performance on par with or exceeding Google's reported metrics. The model supports zero-shot image classification, multi-modal embedding retrieval, and cross-modality search.
Architecture and Training
The model uses a dual-encoder design: EfficientNet for vision encoding and BERT for text encoding, trained with contrastive learning. The COYO-700M dataset (actually containing 747 million image-text pairs) was collected from CommonCrawl (October 2020 to August 2021) and underwent specific filtering:
- Image-level filtering: removed images smaller than 5KB, aspect ratio greater than 3.0, minimum dimension below 200 pixels, and NSFW scores above 0.5 from OpenNSFW2 and GantMan/NSFW models.
- Text-level filtering: English-only via cld3, removed texts with length ≤5 characters, no noun form, fewer than 3 words or more than 256 words, length over 1000, texts appearing more than 10 times, and NSFW content.
- Deduplication: removed duplicate (image_phash, text) pairs, including against external datasets (ImageNet, MS-COCO, CC-3M/12M, Flickr-30K).
Dataset Comparison
| Feature | COYO-700M | LAION 2B | ALIGN 1.8B |
|---|---|---|---|
| Image-text similarity scores | Provided as metadata (CLIP ViT-B/32 and ViT-L/14); nothing filtered out | Provided; only examples above 0.28 threshold | Minimal, frequency-based filtering |
| NSFW filtering | On images and text | On images | Google Cloud Vision API |
| Face recognition data | Provided as metadata | None | N/A |
| Pair count | 700 million (747M actual) | 2 billion | 1.8 billion |
| Source | CommonCrawl Oct 2020–Aug 2021 | CommonCrawl 2014–2020 | N/A |
| Aesthetic score | Yes | Partial | N/A |
| Watermark score | More robust | Yes | N/A |
| Public availability | Hugging Face Hub | Hugging Face Hub | Not public |
The model is intended as a research output for AI researchers studying zero-shot classification, robustness, generalization, and the capabilities and biases of vision-language models.
best for
- ·Zero-shot image classification without task-specific training
- ·Multi-modal image and text embedding retrieval
- ·Cross-modal search with complex text and image queries
FAQ
It is best for zero-shot image classification and multi-modal embedding retrieval, allowing you to classify images or search across images and text without task-specific fine-tuning.
It uses a dual-encoder architecture with EfficientNet as the vision encoder and BERT as the text encoder, trained with contrastive learning.
It was trained on the open-source COYO-700M dataset, which contains 747 million image-text pairs from CommonCrawl web pages.
You can call the model using the gigarouter OpenAI-compatible endpoint with your API key, sending text and image inputs for zero-shot classification or embedding retrieval.
Input is a text prompt and an image; output is either classification probabilities (logits) or separate text and image embeddings.
We're benchmarking and onboarding ALIGN Base as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.