Infinity Parser 7B
infly/Infinity-Parser-7B
published Oct 2025 · updated Feb 2026
Infinity Parser 7B is a vision-language model that parses scanned documents into structured text using reinforcement learning with layout-aware rewards.
specs
| Task | Scanned document parsing (OCR, table and formula extraction, reading order detection) |
| Architecture | Vision-Language Model (VLM) based on Qwen2.5-VL-7B |
| Parameters | 7B |
| License | Apache 2.0 |
about this model
Infinity-Parser-7B is a vision-language model for end-to-end scanned document parsing, trained with reinforcement learning to preserve layout and content fidelity.
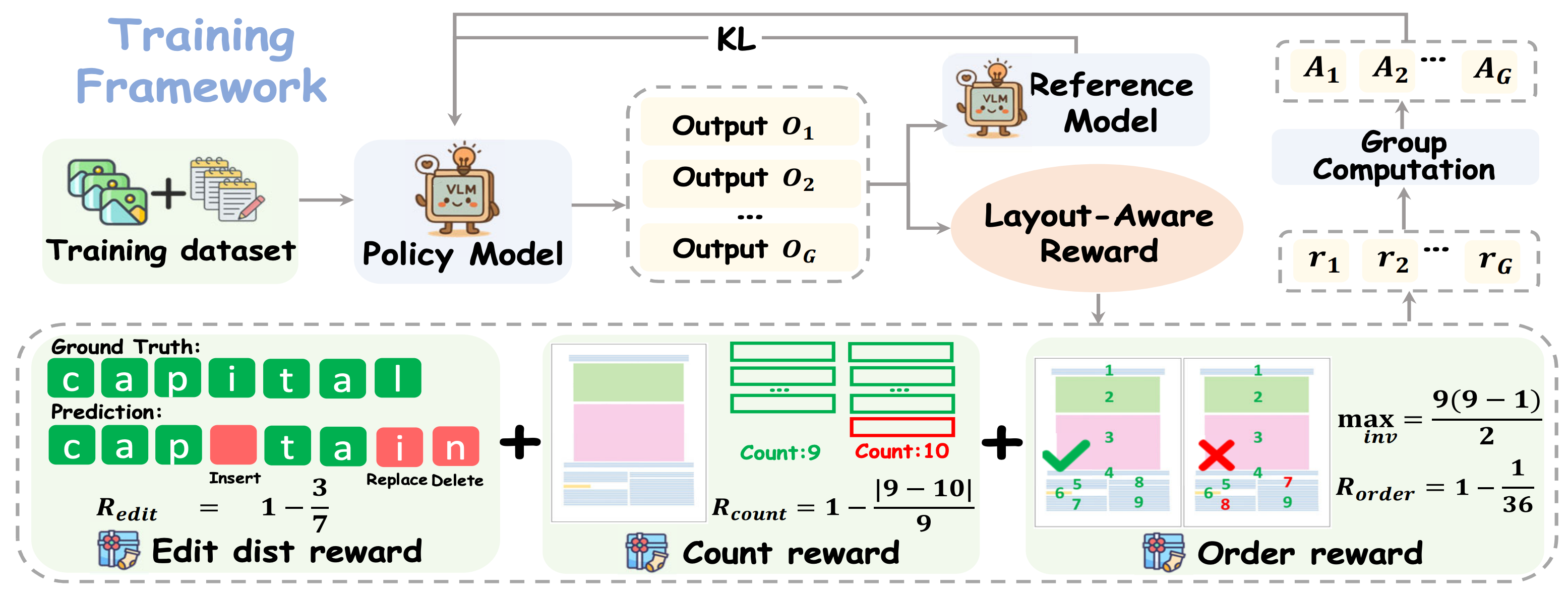
The model uses the LayoutRL framework, optimizing a composite reward of normalized edit distance, paragraph count accuracy, and reading order preservation. It was trained on Infinity-Doc-400K, a dataset of 400K scanned documents with rich layout variations and structural annotations.
On benchmarks including OmniDocBench, olmOCR-Bench, PubTabNet, and FinTabNet, Infinity-Parser-7B achieves state-of-the-art performance across diverse document types, languages (English and Chinese), and structural complexities. It substantially outperforms both specialized document parsing pipelines and general-purpose vision-language models while retaining near-equivalent general multimodal understanding (base model: Qwen2.5-VL-7B, evaluated via LMMS-Eval).
Architecture
The training framework combines reinforcement fine-tuning with edit distance, layout, and order-based rewards.
Benchmark Results
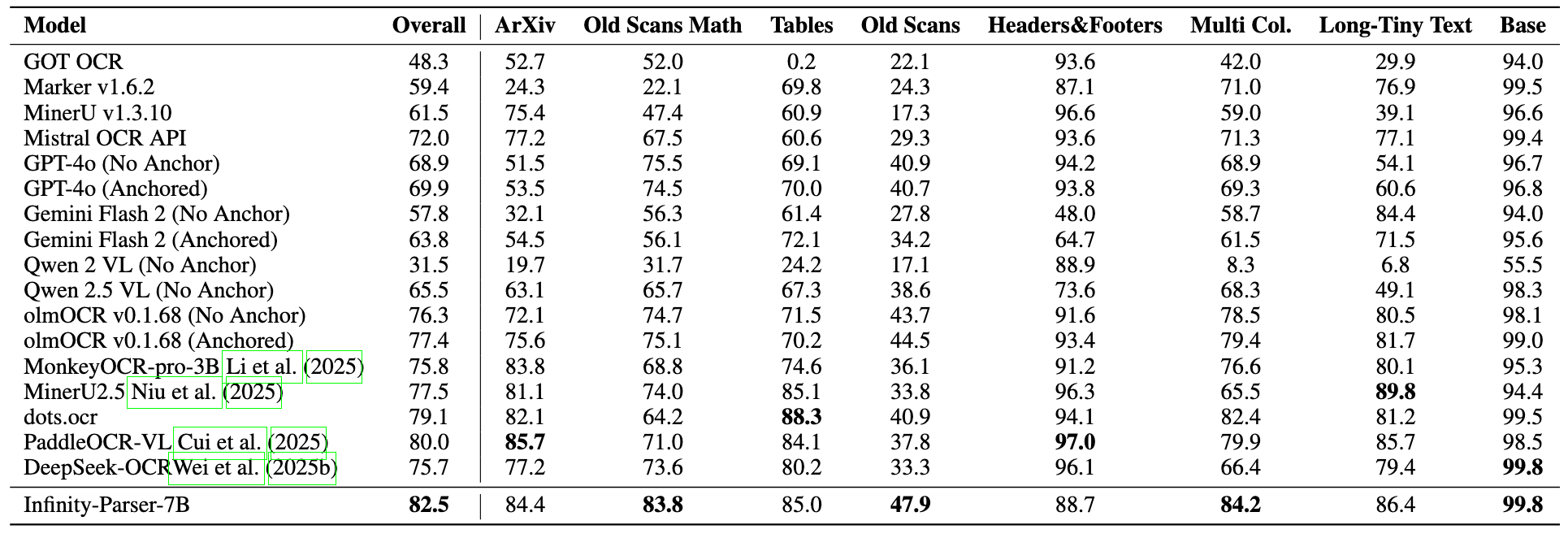
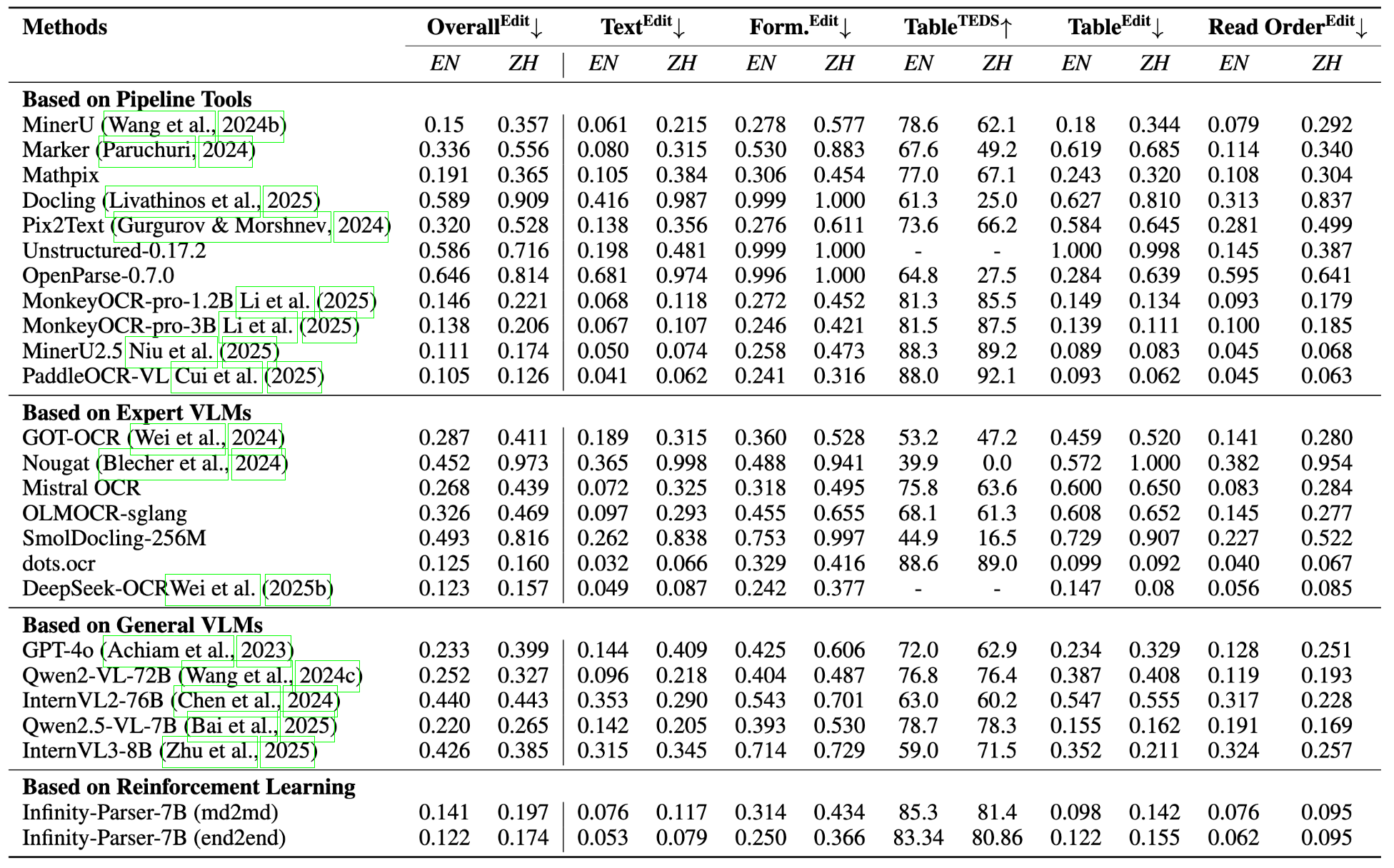
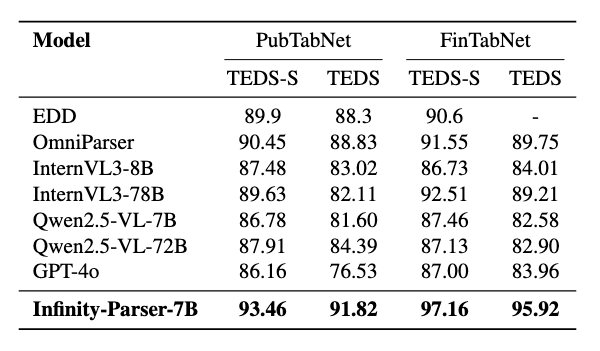

Visual Comparison
Limitations
- Does not provide layout or bounding box information, limiting support for downstream structured reconstruction.
- Lacks perception and structured extraction for charts and figures.
The model was accepted as a Findings paper at ACL 2026. Licensed under Apache 2.0. For further details, see the arXiv paper and GitHub repository.
best for
- ·Extracting text and tables from scanned documents with high structural fidelity
- ·Parsing multi-lingual documents (English and Chinese) for downstream data processing
- ·Reading order detection and formula extraction from academic papers and reports
FAQ
It is a vision-language model for end-to-end scanned document parsing, including OCR, table and formula extraction, and reading order detection.
It is built on Qwen2.5-VL-7B.
It is licensed under Apache 2.0.
No, the current model does not provide layout or bounding box information.
Use the gigarouter OpenAI-compatible endpoint with an API key.
We're benchmarking and onboarding Infinity Parser 7B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.