Japanese Reranker XSmall V2
hotchpotch/japanese-reranker-xsmall-v2
published May 2025 · updated May 2026
Japanese Reranker XSmall V2 is a fast, compact rerank model that re-ranks Japanese text pairs using a ModernBert-based architecture.
specs
| Task | Reranking |
| Architecture | ModernBert (based on ruri-v3-pt-30m) |
| Layers | 10 |
| Hidden Size | 256 |
| License | MIT |
about this model
hotchpotch/japanese-reranker-xsmall-v2 is a reranker model that scores query–passage relevance to improve retrieval accuracy in Japanese RAG pipelines. It is the second-smallest model in the v2 series, balancing high performance with extremely fast inference.
Architecture and strengths
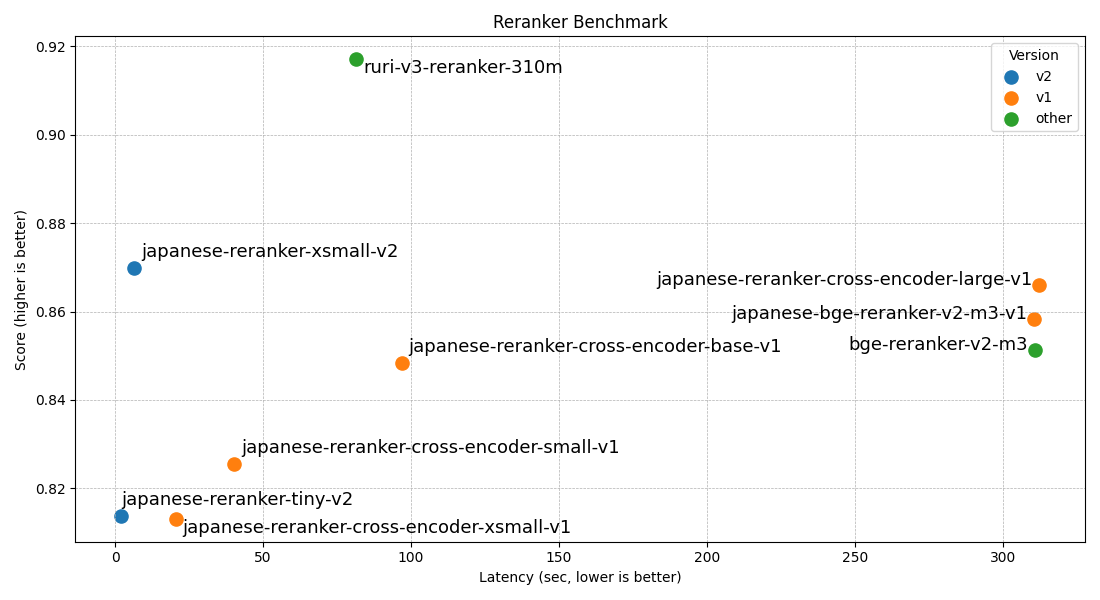
Built on ModernBert (ruri-v3-pt-30m), the model uses 10 transformer layers with a hidden size of 256. Despite its compact size, it achieves an average benchmark score of 0.8699 across four Japanese retrieval datasets—outperforming many larger cross‑encoder variants from the v1 series. The model runs efficiently on GPU (6.5 s for ~150 k pairs using flash‑attention 2), on Apple Silicon (MPS), and on CPU. ONNX quantised versions (for AVX2 and ARM64) are also available for edge or CPU-only deployments, making the model suitable for low‑latency and resource‑constrained environments.
Benchmark performance
| Dataset | Score |
|---|---|
| JQaRA | 0.7403 |
| JaCWIR | 0.9409 |
| MIRACL | 0.8206 |
| JSQuAD | 0.9776 |
The model was trained using knowledge distillation from larger teacher models (japanese-reranker-cross-encoder-large‑v1 and japanese-bge-reranker-v2‑m3‑v1) and a single‑epoch training strategy to prevent overfitting. Training data includes multiple Japanese retrieval datasets plus hard negatives (hotchpotch/japanese-reranker-v2-hard-negatives).
best for
- ·Improving retrieval accuracy in Japanese RAG systems
- ·Running on CPU or edge devices for low-latency reranking
- ·Re-ranking search results for Japanese documents
FAQ
The model expects pairs of query and passage text, returning a relevance score between 0 and 1.
It processes about 150,000 pairs in 6.5 seconds on an RTX 5090 with flash attention.
It is released under the MIT License.
Yes, it is designed to run efficiently on CPU and Apple Silicon, with ONNX quantized versions available for even faster inference.
Use the OpenAI-compatible endpoint at gigarouter with your API key, sending the model name and input pairs as specified in the documentation.
We're benchmarking and onboarding Japanese Reranker XSmall V2 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.