SigLIP 2 So400m
google/siglip2-so400m-patch16-naflex
published Feb 2025 · updated Feb 2025
SigLIP 2 So400m is a zero-shot-image model that extends SigLIP with improved semantic understanding, localization, and dense features for multilingual vision-language tasks.
specs
| Task | Zero-shot image classification, image-text retrieval, vision encoder |
| Architecture | SigLIP 2 Vision Transformer (ViT) So400m/16 patch16 NaFlex with native aspect ratio and multiple resolution support |
| Parameters | 400 million |
about this model
google/siglip2-so400m-patch16-naflex is a zero-shot image classification and vision-language encoding model that extends the SigLIP pretraining objective with captioning-based pretraining, self-supervised losses (self-distillation, masked prediction), and adaptive resolution handling for improved semantic understanding, localization, and dense features. It supports multiple resolutions while preserving the input's native aspect ratio via the NaFlex (non-uniform aspect ratio flexible) variant.
SigLIP 2 models are trained on the WebLI dataset (Chen et al., 2023) using up to 2048 TPU-v5e chips. The So400m/16 variant contains 400 million parameters and uses a Gemma tokenizer with a 256k vocabulary. The model can be used for zero-shot image classification, image-text retrieval, or as a vision encoder for vision-language models (VLMs).
Evaluation Results
The following table from the SigLIP 2 paper reports zero-shot ImageNet accuracy and COCO retrieval scores for the So400m/16 variant at different input resolutions:
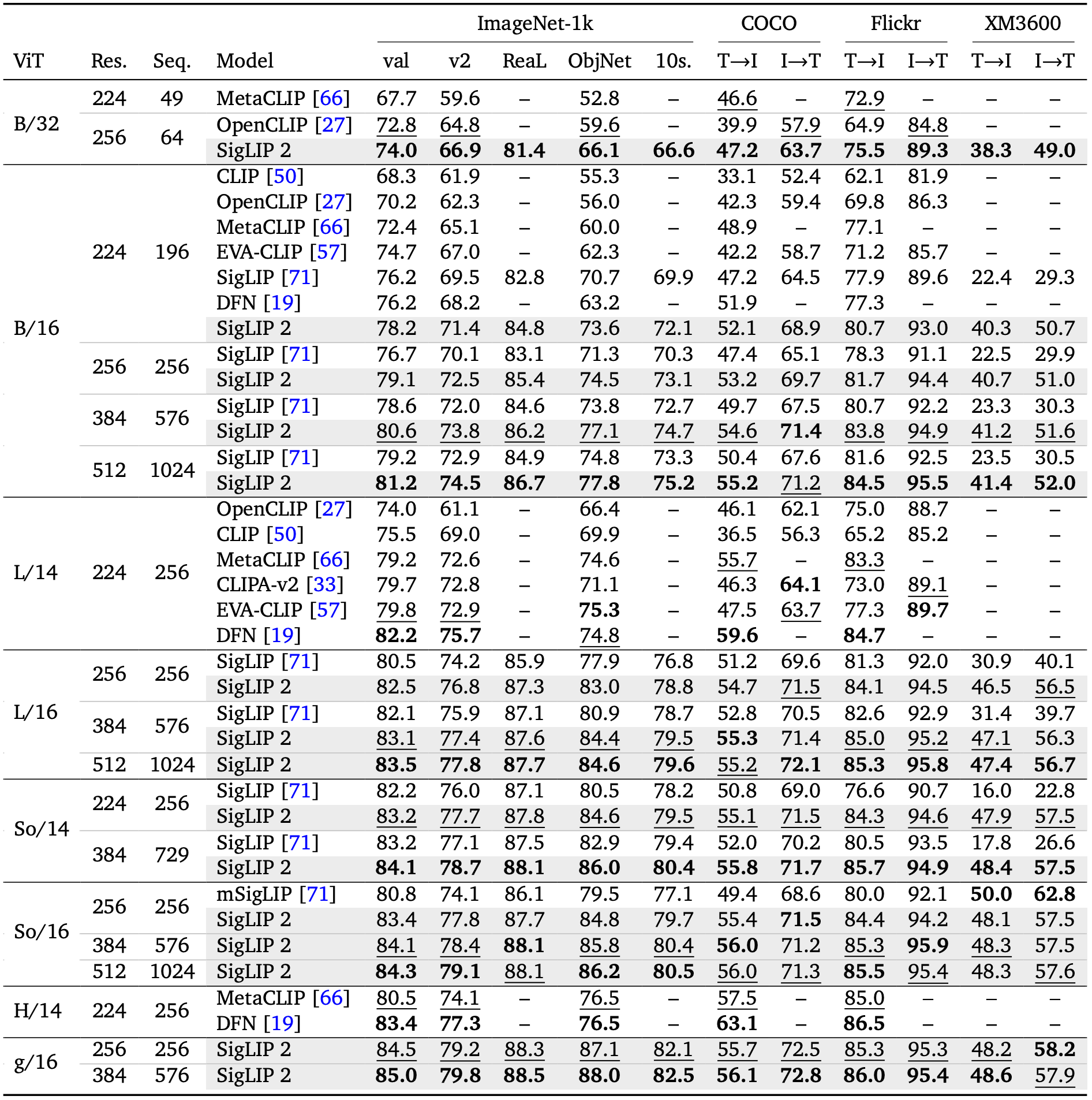
- Zero-shot ImageNet accuracy: 83.4% at 256px, 84.1% at 384px, 84.3% at 512px.
- COCO Text→Image retrieval: 56.0 at 512px.
- COCO Image→Text retrieval: 71.3 at 512px.
Compared to the original SigLIP, SigLIP 2 shows consistent improvements across zero-shot classification, retrieval, and dense prediction tasks, with stronger multilingual understanding and improved fairness due to de-biasing techniques in the training data mixture.
best for
- ·Zero-shot classification of images using natural language labels
- ·Multilingual image-text retrieval across diverse domains
- ·Vision backbone for Vision-Language Models (VLMs)
FAQ
It has 400 million parameters.
The NaFlex variant supports multiple resolutions including 224px, 256px, 384px, and 512px while preserving native aspect ratio.
SigLIP 2 outperforms SigLIP at all scales on zero-shot classification, image-text retrieval, and dense prediction tasks.
Call the gigarouter OpenAI-compatible endpoint with your API key and appropriate input format.
It is pre-trained on the WebLI dataset (Chen et al., 2023).
We're benchmarking and onboarding SigLIP 2 So400m as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.