SigLIP 2 So400m
google/siglip2-so400m-patch16-512
published Feb 2025 · updated Feb 2025
SigLIP 2 So400m is a zero-shot-image model that extends the SigLIP objective with captioning, self-supervised losses, and online data curation for improved semantic understanding, localization, and dense features.
specs
| Task | Zero-shot image classification, image-text retrieval, vision encoder |
| Architecture | SigLIP 2 (Vision Transformer based) |
| Parameters | 1.14B (So400m variant) |
| License | Apache 2.0 |
about this model
google/siglip2-so400m-patch16-512 is a zero-shot image classification and vision-language encoder model that extends the SigLIP pretraining objective with captioning-based pretraining, self-supervised losses (self-distillation, masked prediction), and online data curation into a unified recipe for improved semantic understanding, localization, and dense features.
This model, part of the SigLIP 2 family, is the So400m variant with approximately 1.14 billion parameters. It is licensed under Apache 2.0. The model supports zero-shot image classification and image-text retrieval, and can serve as a vision encoder for Vision-Language Models (VLMs). It was pretrained on the WebLI dataset using up to 2048 TPU-v5e chips.
Key Strengths
- Improved performance over original SigLIP across all model scales in zero-shot classification, image-text retrieval, and transfer for VLMs.
- Significant improvements on localization and dense prediction tasks.
- Supports multiple resolutions and preserves the input's native aspect ratio.
- Trained on a diverse data-mixture with de-biasing techniques for better multilingual understanding and improved fairness.
Evaluation Results
The following table from the SigLIP 2 paper shows evaluation results for the model family:
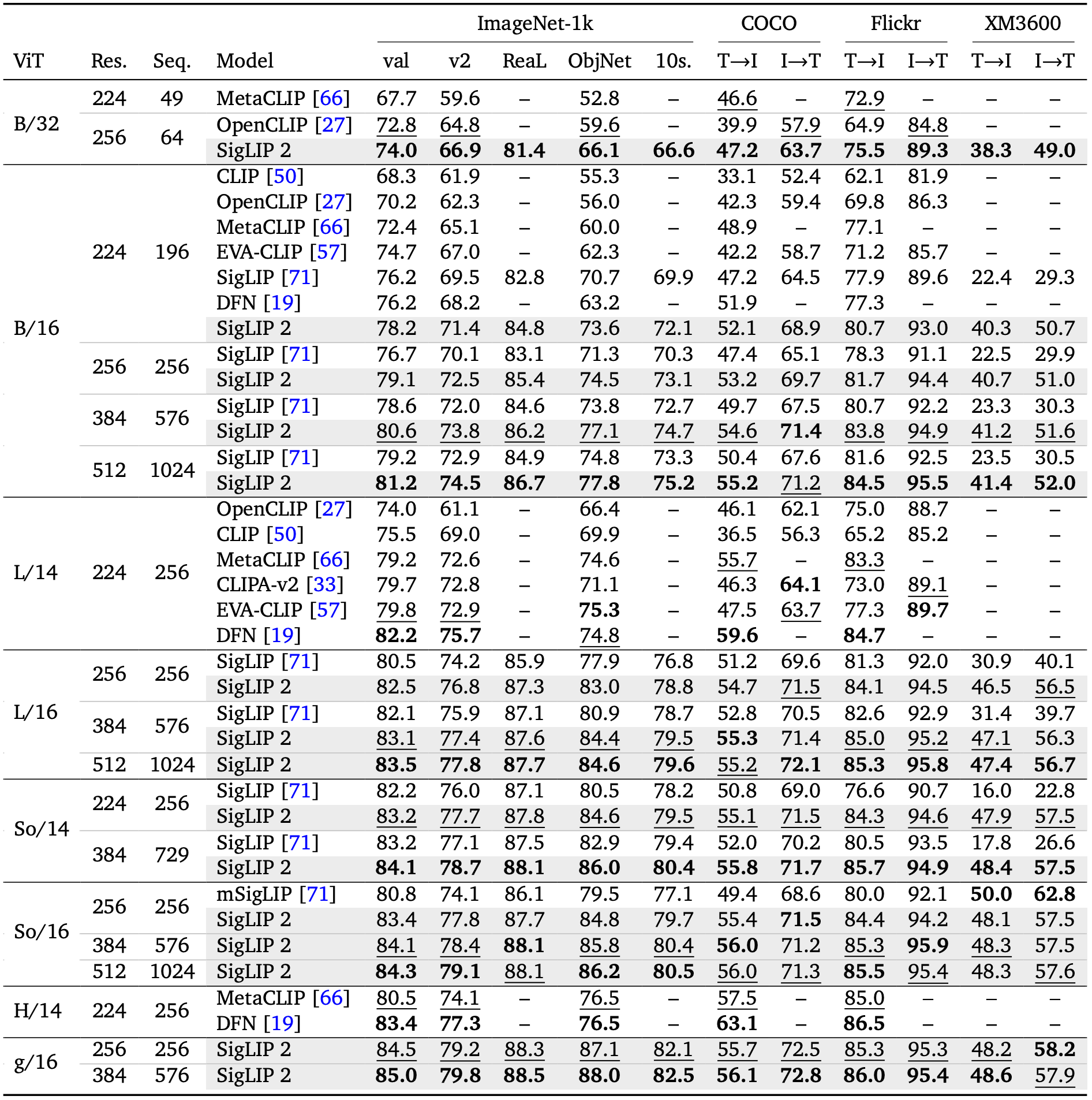
Additional Details
- The So400m variant has 1,136,556,698 parameters (F32).
- The full model family includes four sizes: ViT-B (86M), L (303M), So400m (400M), and g (1B).
- Training incorporated captioning-based pretraining, self-distillation, masked prediction losses, and online data curation.
- Variants support multiple resolutions and preserve the input's native aspect ratio.
- Training data included de-biasing techniques for improved multilingual understanding and fairness.
For further details, refer to the SigLIP 2 paper and the SigLIP documentation.
best for
- ·Zero-shot image classification with arbitrary candidate labels
- ·Image-text retrieval across multiple languages
- ·Extracting visual features for Vision-Language Models (VLMs)
FAQ
It excels at zero-shot image classification, image-text retrieval, and as a vision encoder for VLMs, with improvements in localization and dense prediction tasks.
The So400m variant has approximately 1.14 billion parameters, confirmed via Hugging Face safetensors metadata.
The model is licensed under Apache 2.0, as indicated by the Hugging Face model page tags.
Input: images (URL or base64) and text candidate labels; output: classification scores or embeddings. For retrieval, image and text pairs. Use the gigarouter OpenAI-compatible endpoint with an API key.
Use the OpenAI-compatible endpoint with your API key. The endpoint URL and model name will be provided in your gigarouter dashboard. Send a request with image and text inputs as per the zero-shot-image classification schema.
We're benchmarking and onboarding SigLIP 2 So400m as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.