SigLIP 2 So400m
google/siglip2-so400m-patch14-384
published Feb 2025 · updated Feb 2025
SigLIP 2 So400m is a zero-shot-image model that performs image classification, image-text retrieval, and acts as a vision encoder with improved semantic understanding, localization, and dense features.
specs
| Task | Zero-shot image classification, image-text retrieval, vision encoding |
| Architecture | SigLIP 2 (ViT-So400m, patch14, 384x384 resolution) |
| Parameters | 400 million |
| Training Data | WebLI dataset (multilingual image-text pairs) |
about this model
google/siglip2-so400m-patch14-384 is a zero-shot image classification and image-text retrieval model that extends the SigLIP training objective with a unified recipe incorporating captioning pretraining, self-supervised losses (self-distillation, masked prediction), and online data curation. It serves as a vision-language encoder capable of dense prediction and localization tasks.
Key Strengths
- Improved semantic understanding, localization, and dense feature extraction compared to the original SigLIP across all model scales.
- Supports multiple resolutions and preserves native aspect ratio, enhancing adaptability to varied input images.
- Multilingual understanding and fairness are improved through de-biasing techniques and a more diverse training data mixture (WebLI dataset).
- Four model variants released: ViT-B (86M), L (303M), So400m (400M), and g (1B). This So400m variant offers a balance of performance and inference cost.
Evaluation Results
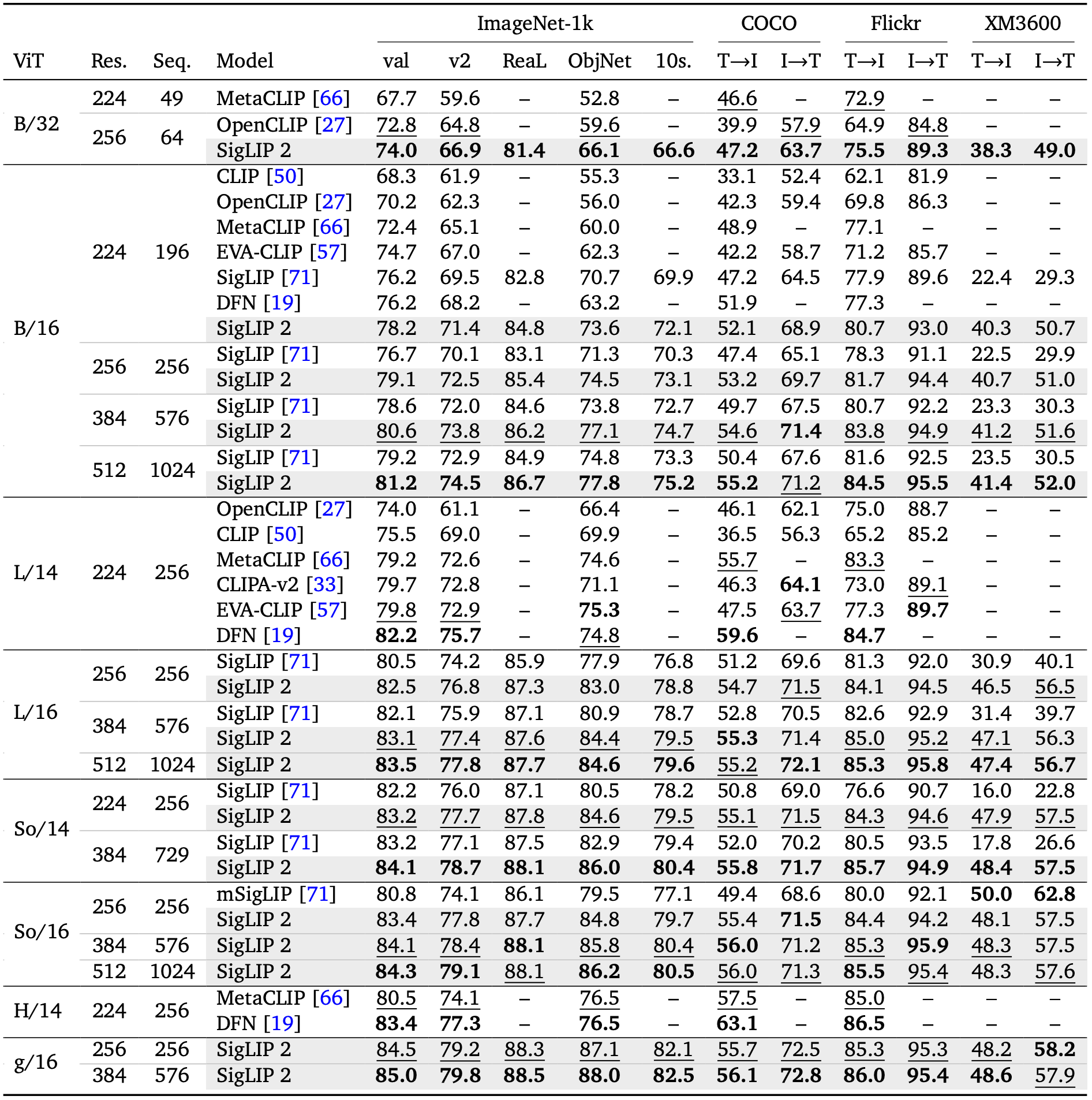
The table below, reproduced from the SigLIP 2 paper, shows model performance on zero-shot classification, image-text retrieval, and transfer tasks. The So400m variant outperforms its SigLIP counterpart at the same scale.
Training Details
Pre‑trained on the WebLI dataset using up to 2048 TPU‑v5e chips. The training recipe combines sigmoid loss (original SigLIP), a decoder loss, global-local masked prediction loss, and active data curation via distillation.
best for
- ·Zero-shot classification of images without fine-tuning
- ·Multilingual image-text retrieval and search
- ·Vision encoder for multimodal LLMs and VLMs
- ·Dense prediction tasks like localization and segmentation
FAQ
It excels at zero-shot image classification, image-text retrieval, and as a vision encoder for VLMs, with improved localization and dense features.
SigLIP 2 adds decoder loss, self-supervised losses (self-distillation, masked prediction), and online data curation, resulting in better performance on zero-shot, retrieval, and dense prediction tasks at all model scales.
It accepts images (384x384 resolution) and text labels. You can use the Hugging Face pipeline for zero-shot classification or extract image embeddings via AutoModel.
Use the OpenAI-compatible endpoint with your API key to send images and candidate labels for zero-shot classification.
SigLIP 2 So400m has 400 million parameters and was pre-trained on the large-scale multilingual WebLI dataset.
We're benchmarking and onboarding SigLIP 2 So400m as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.