SigLIP 2 Giant
google/siglip2-giant-opt-patch16-384
published Feb 2025 · updated Feb 2025
SigLIP 2 Giant is a zero-shot-image model that extends SigLIP with improved semantic understanding, localization, and dense features for tasks like zero-shot classification and image-text retrieval.
specs
| Task | Zero-Shot Image Classification, Image-Text Retrieval, Vision Encoder |
| Architecture | ViT-giant/16 with OPT decoder, patch size 16, 384 resolution |
| Parameters | 1 billion |
| Input Resolution | 384x384 |
| Training Data | WebLI dataset |
about this model
google/siglip2-giant-opt-patch16-384 is a vision-language encoder model specialized for zero-shot image classification, image-text retrieval, and as a visual backbone for vision-language models (VLMs). It is the giant (1B parameter) variant of SigLIP 2, built on an OPT decoder with patch size 16 and 384 resolution, using a sigmoid loss training objective. The model extends the original SigLIP with a unified recipe that combines captioning-based pretraining, self-supervised losses (self-distillation, masked prediction), and online data curation, resulting in improved semantic understanding, localization, and dense feature extraction.
Key Improvements
- Enhanced zero-shot classification and retrieval performance across all model scales compared to SigLIP.
- Significant gains on localization and dense prediction tasks.
- Support for multiple resolutions and native aspect ratio preservation.
- Multilingual understanding and improved fairness through de-biased training on the WebLI dataset (over 100 languages).
Benchmark Performance
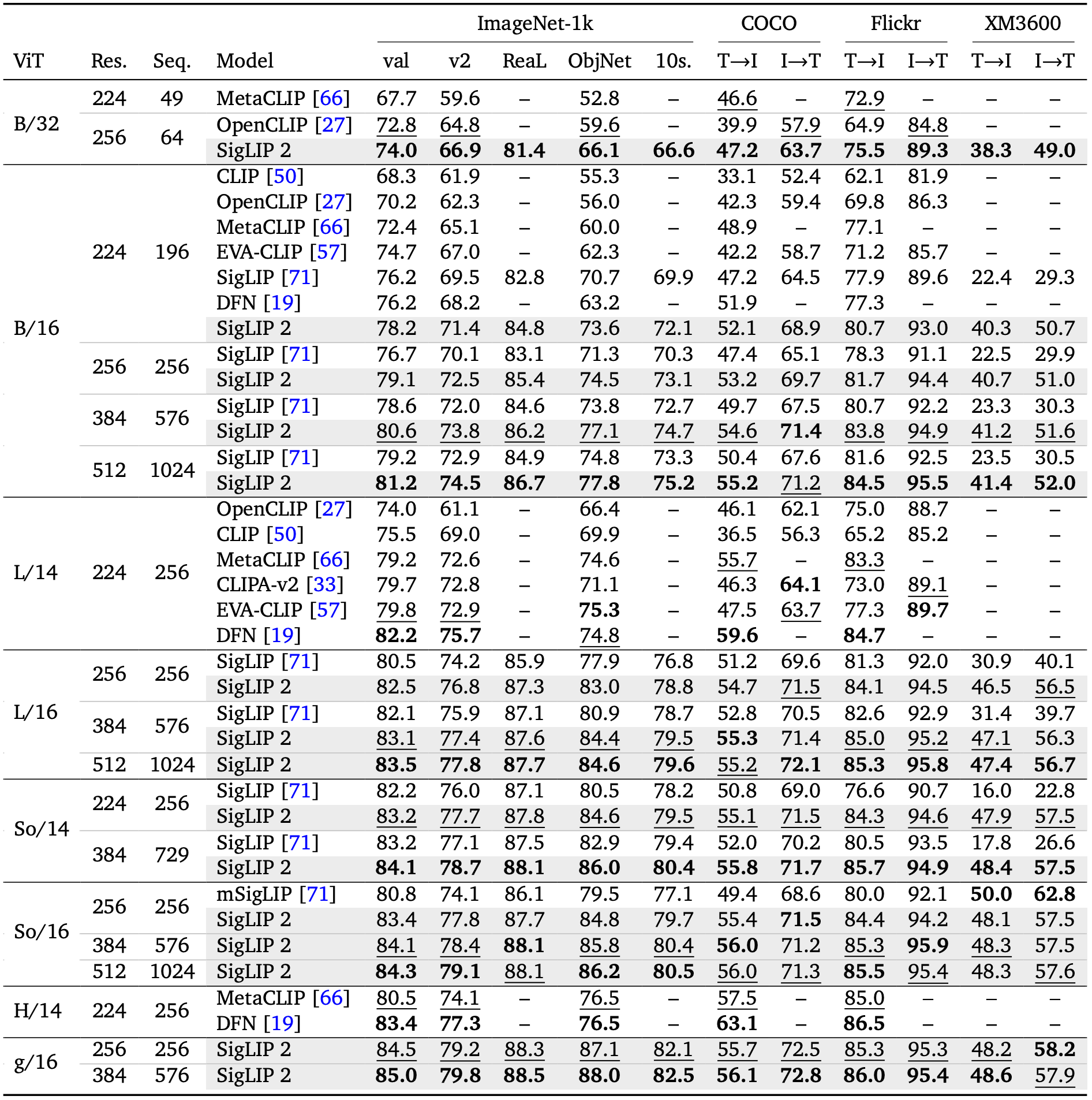
The evaluation results from the SigLIP 2 paper are shown below. For context, the So400m variant at 384 resolution achieves 84.1% ImageNet zero-shot accuracy, 56.0 COCO text-to-image R@1, and 71.2 COCO image-to-text R@1.
Training Details
Pre-trained on the WebLI dataset using up to 2048 TPU-v5e chips. The model uses a Gemma tokenizer with a 256k vocabulary. Checkpoints are available via Hugging Face and in npz format from Google Cloud Storage. No explicit license is specified for the model weights.
best for
- ·Zero-shot image classification with arbitrary candidate labels
- ·Image-text retrieval (e.g., finding images from text descriptions)
- ·Vision encoder for Vision-Language Models (VLMs)
- ·Localization and dense prediction tasks
FAQ
SigLIP 2 adds captioning-based pretraining, self-supervised losses, and online data curation, leading to better zero-shot, retrieval, and dense prediction performance.
1 billion parameters.
It expects images and candidate labels; images can be provided as URLs or loaded into a PIL image.
Use the gigarouter OpenAI-compatible endpoint with an API key, sending an image and candidate labels for zero-shot classification.
The model card does not specify a license; check the paper and repository for details.
We're benchmarking and onboarding SigLIP 2 Giant as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.