SigLIP 2 Base
google/siglip2-base-patch16-naflex
published Feb 2025 · updated Feb 2025
SigLIP 2 Base is a zero-shot-image model that extends SigLIP with improved semantic understanding, localization, and dense features.
specs
| Task | Zero-shot image classification, image-text retrieval, vision encoder |
| Architecture | ViT-B/16 with NaFlex (native aspect ratio and flexibility) |
| Parameters | 86M |
| Training Data | WebLI dataset (100+ languages) |
about this model
Architecture and Capabilities
The model (ViT-B, 86M parameters) extends the SigLIP pretraining objective with captioning-based pretraining, self-supervised losses (self-distillation, masked prediction), and online data curation. It uses the Gemma tokenizer with a 256k vocabulary. The NaFlex variant preserves the input's native aspect ratio and supports multiple resolutions, requiring adapted preprocessing not compatible with standard SigLIP inference code.
Training Details
Pre-trained on the WebLI dataset (Chen et al., 2023) with a diverse data mixture incorporating de-biasing techniques for improved multilingual understanding and fairness. Training used up to 2048 TPU-v5e chips.
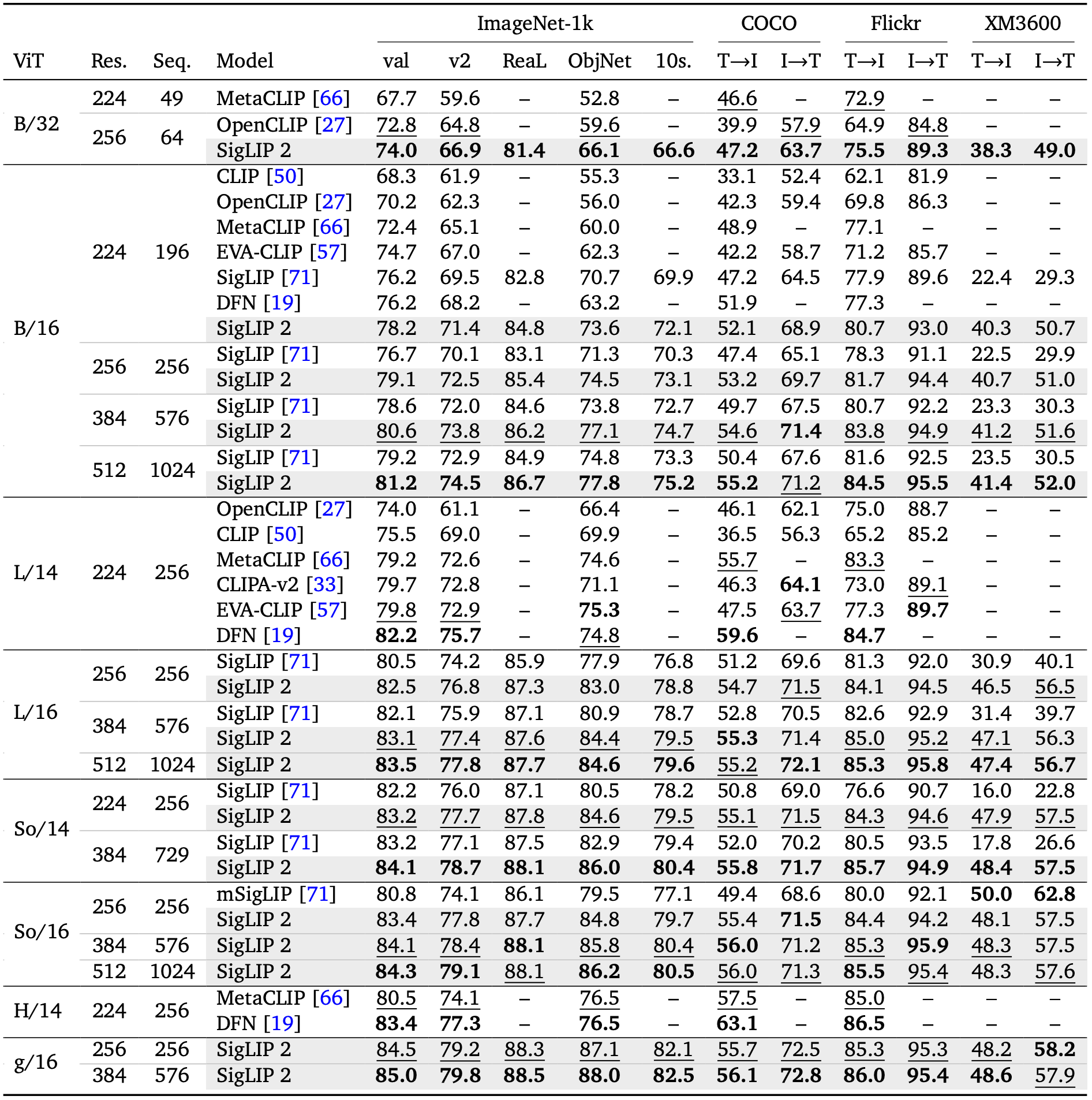
Benchmark Results
At 224px resolution, SigLIP 2 Base achieves:
- 78.2% ImageNet zero-shot accuracy
- 52.1 COCO text-to-image recall
- 68.9 COCO image-to-text recall
The model outperforms its SigLIP counterpart at the same scale across zero-shot classification, retrieval, and transfer performance for Vision-Language Models (VLMs), with significant gains on localization and dense prediction tasks.
Model Variants
SigLIP 2 is released in four sizes: ViT-B (86M), L (303M), So400m (400M), and g (1B). This base model is the smallest, optimized for efficient inference.
best for
- ·Zero-shot image classification with any set of candidate labels
- ·Image-text retrieval (searching images by text)
- ·Vision encoder for Vision-Language Models (VLMs)
FAQ
Zero-shot image classification, image-text retrieval, and as a vision encoder for VLMs.
SigLIP 2 improves semantic understanding, localization, dense features, multilingual understanding, and fairness. At base size, it achieves 78.2% ImageNet zero-shot accuracy.
It preserves the input's native aspect ratio and supports multiple resolutions, unlike fixed-resolution variants.
86M parameters for the base ViT-B/16 model.
Use the gigarouter OpenAI-compatible endpoint with an API key.
We're benchmarking and onboarding SigLIP 2 Base as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.