SigLIP 2 Base
google/siglip2-base-patch16-256
published Feb 2025 · updated Feb 2025
SigLIP 2 Base is a zero-shot-image model that extends the SigLIP pretraining objective with captioning, self-supervised losses, and online data curation for improved semantic understanding, localization, and dense features.
specs
| Task | Zero-Shot Image Classification, Image-Text Retrieval, Vision Encoder |
| Architecture | ViT-B/16 (Vision Transformer Base, patch size 16) |
| Parameters | 86M |
| License | Apache 2.0 |
about this model
SigLIP 2 Base is a vision-language encoder model for zero-shot image classification and image-text retrieval, built on the SigLIP framework with an extended training recipe that improves semantic understanding, localization, and dense feature extraction. With 86 million parameters, it is designed for efficient inference while maintaining strong performance across a range of vision-language tasks.
The model is pre-trained on the WebLI dataset and further refined using a diverse multilingual data mixture with de-biasing techniques, resulting in better multilingual understanding and fairness. The training incorporates captioning-based pretraining, self-supervised losses (self-distillation, masked prediction), and online data curation. SigLIP 2 also supports multiple input resolutions and preserves the native aspect ratio of images during inference.
Benchmark Performance
On standard zero-shot and retrieval benchmarks, the 256px base variant achieves the following results:
| Benchmark | Metric | Score |
|---|---|---|
| ImageNet | Zero-shot top-1 accuracy | 79.1% |
| COCO (text-to-image) | Recall@1 | 53.2 |
| COCO (image-to-text) | Recall@1 | 69.7 |
Further evaluation results from the paper are shown below:
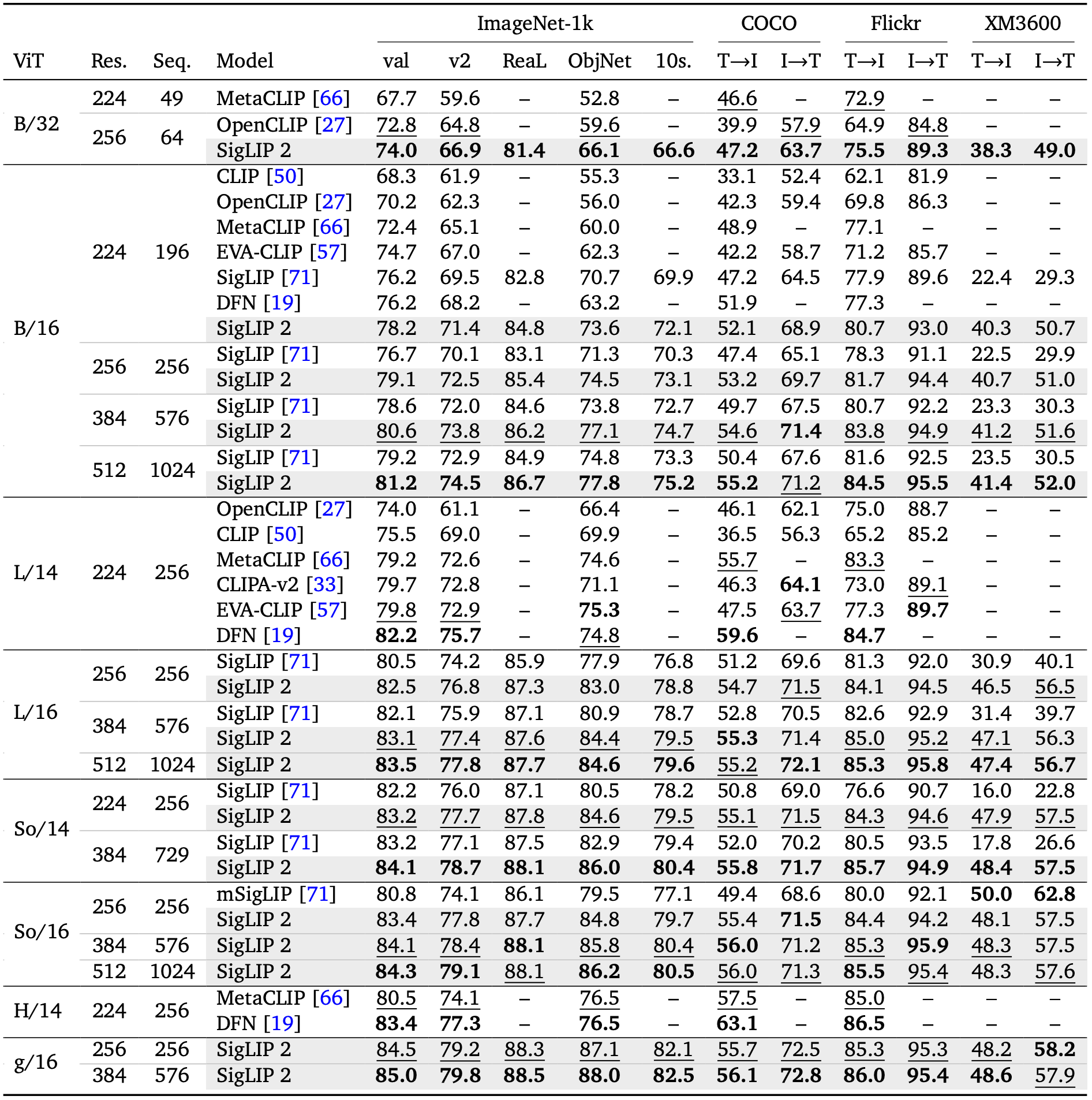
Compared to the original SigLIP, the new training recipe yields substantial gains on localization and dense prediction tasks, including semantic segmentation, depth estimation, and referring expression comprehension. The model also serves as a drop-in vision encoder for Vision-Language Models (VLMs), offering improved transfer performance at no additional inference cost.
best for
- ·Zero-shot image classification with custom label sets
- ·Image-text retrieval (searching images by text or vice versa)
- ·Vision encoder for multimodal models and VLMs
FAQ
The API accepts an image URL or base64-encoded image and a list of candidate text labels for zero-shot classification, or an image and text pair for retrieval.
Use the gigarouter OpenAI-compatible endpoint with your API key, sending a POST request with the image and text inputs in the required format.
SigLIP 2 Base (B/16, 256px) achieves 79.1% zero-shot accuracy on ImageNet.
The model is released under the Apache 2.0 license.
SigLIP 2 Base outperforms the original SigLIP Base on zero-shot classification, image-text retrieval, and dense prediction tasks, with improved multilingual understanding and fairness.
We're benchmarking and onboarding SigLIP 2 Base as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.