SigLIP SoViT-400m
google/siglip-so400m-patch14-384
published Jan 2024 · updated Sep 2024
SigLIP SoViT-400m is a zero-shot image classification and image-text retrieval model that uses a sigmoid loss function for language-image pre-training.
specs
| Task | Zero-shot image classification, image-text retrieval |
| Architecture | SoViT-400m (shape-optimized Vision Transformer) |
| Parameters | 878M |
| License | Apache 2.0 |
about this model
google/siglip-so400m-patch14-384 is a zero-shot image classification model that combines a shape-optimized Vision Transformer (SoViT-400m) with the SigLIP (Sigmoid Loss for Language Image Pre-training) approach. Unlike standard contrastive learning with softmax normalization, the sigmoid loss operates directly on image-text pairs without requiring a global view of pairwise similarities. This design enables scaling to larger batch sizes while maintaining strong performance at smaller batch sizes.
The model uses the SoViT-400m architecture, derived from scaling laws for compute-optimal model shape. Pre-trained on the WebLI dataset at 384×384 resolution, it achieves results competitive with models over twice its size. On ILSVRC2012 fine-tuning, SoViT-400m/14 reaches 90.3% accuracy, surpassing ViT-g/14 and approaching ViT-G/14 at less than half the inference cost. Across classification, captioning, VQA, and zero-shot transfer, the shape-optimized backbone delivers strong performance.
Evaluation results for zero-shot classification are shown below, comparing SigLIP to CLIP across multiple datasets.
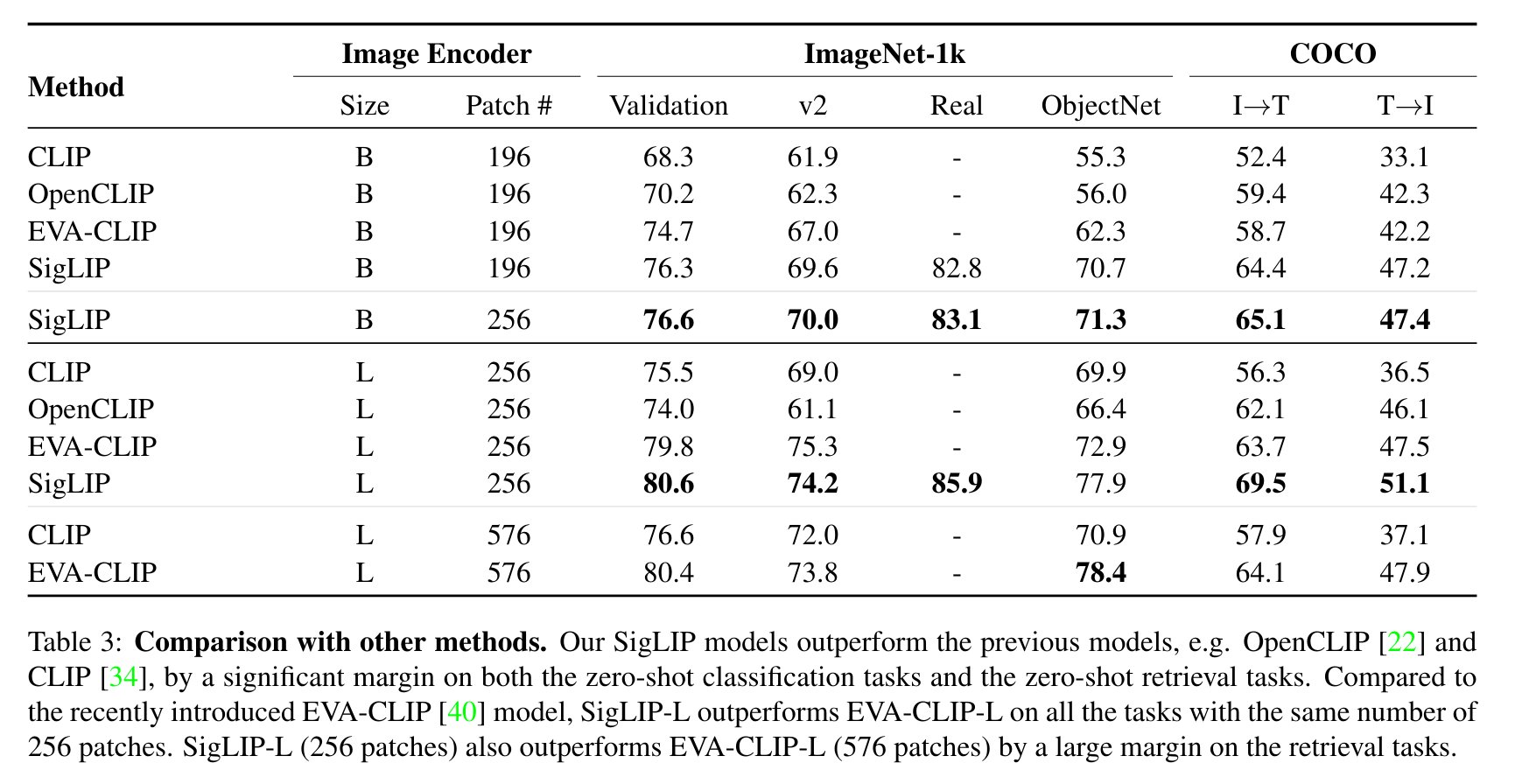
The model contains approximately 878 million parameters and is released under the Apache 2.0 license. It was trained on 16 TPU-v4 chips over three days. Preprocessing resizes images to 384×384 and normalizes with mean 0.5 and std 0.5; text is tokenized to 64 tokens. As a hosted API on gigarouter, it provides OpenAI-compatible endpoints for zero-shot classification and image-text retrieval without requiring local infrastructure.
best for
- ·Zero-shot classification of images with arbitrary text labels
- ·Image-text retrieval and similarity scoring
FAQ
It accepts images (resized to 384x384, normalized with mean 0.5 and std 0.5) and text (tokenized to 64 tokens).
SigLIP uses a pairwise sigmoid loss instead of softmax contrastive loss, which does not require a global view of pairwise similarities and allows scaling to larger batch sizes.
It is released under the Apache 2.0 license.
Use the gigarouter OpenAI-compatible endpoint with your API key, sending an image and candidate text labels for zero-shot classification.
The SoViT-400m/14 architecture achieves 90.3% fine-tuning accuracy on ILSVRC2012.
We're benchmarking and onboarding SigLIP SoViT-400m as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.