siglip large patch16 256
google/siglip-large-patch16-256
published Jan 2024 · updated Sep 2024
A popular open zero-shot image model, with 30.2K downloads a month. gigarouter benchmarks and hosts it as an OpenAI-compatible API.
about this model
google/siglip-large-patch16-256 is a zero-shot image classification and image-text retrieval model that extends the CLIP architecture with a pairwise sigmoid loss function for language-image pre-training. Unlike standard contrastive learning with softmax normalization, the sigmoid loss operates solely on image-text pairs without requiring a global view of pairwise similarities for normalization, enabling effective training at both very large and small batch sizes.
Architecture and Training
The model is pre-trained on the English image-text pairs of the WebLI dataset at 256x256 resolution. Images are resized and normalized across RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5); text is tokenized and padded to 64 tokens. Training used 16 TPU-v4 chips over three days.
Key Strengths
- The sigmoid loss decouples batch size from normalization, allowing scaling up to 1 million pairs while finding 32k sufficient for strong performance.
- A SigLiT variant (SigLIP with Locked-image Tuning) achieves 84.5% ImageNet zero-shot accuracy using only 4 TPUv4 chips trained in 2 days.
- Presented as an ICCV'23 Oral paper.
Benchmark Comparison
The following comparison from the paper shows SigLIP evaluation results against CLIP:
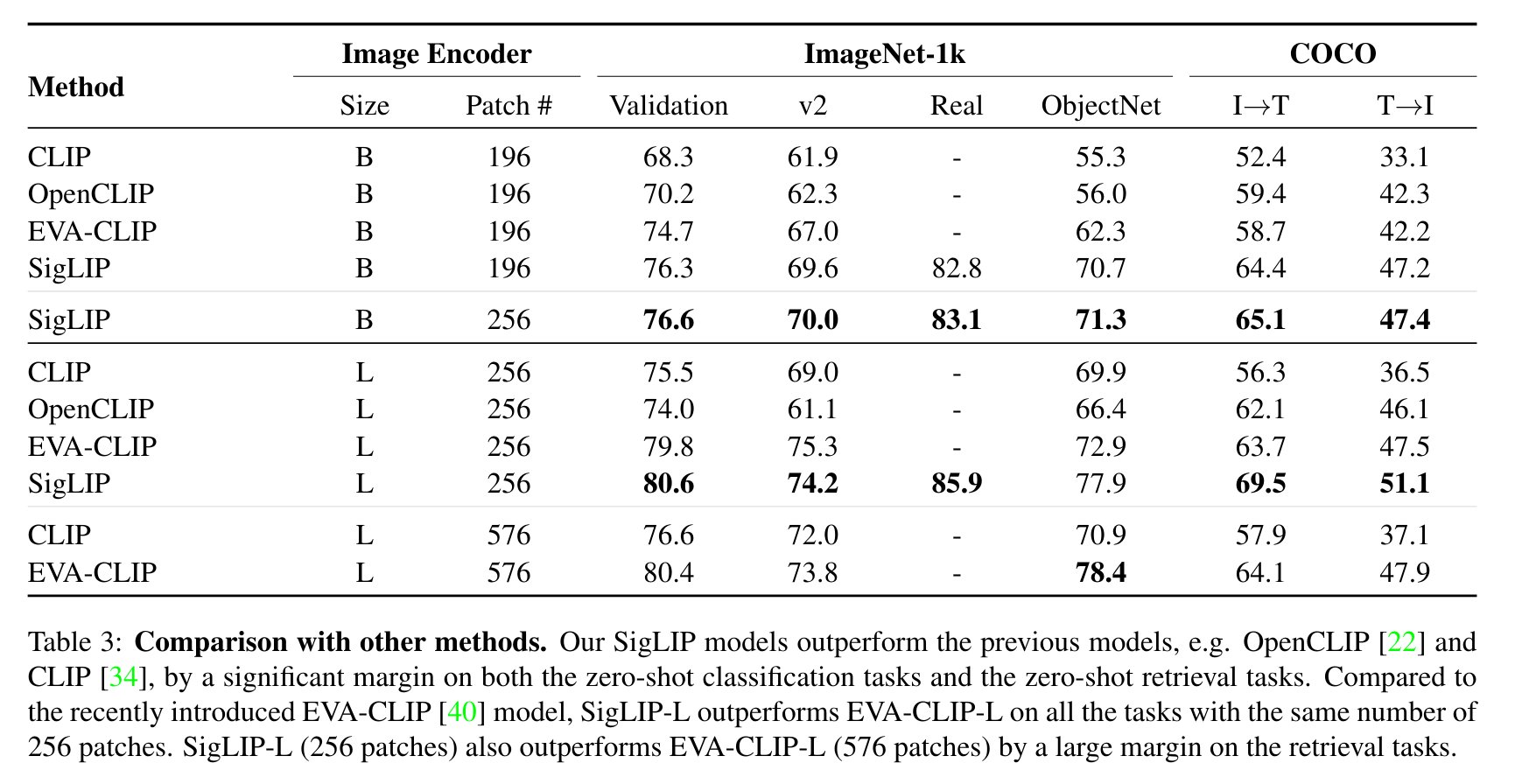
Model Variants
Version v4 of the paper adds results for SigLIP Base, Large, and Shape-Optimized 400M model variants. This specific model is the large-sized variant at 256x256 resolution.
We're benchmarking and onboarding siglip large patch16 256 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.