SigLIP Base
google/siglip-base-patch16-512
published Jan 2024 · updated Sep 2024
SigLIP Base is a zero-shot-image model that uses a pairwise sigmoid loss for language-image pre-training, enabling tasks like zero-shot classification and image-text retrieval.
specs
| Task | Zero-shot image classification, image-text retrieval |
| Architecture | Multimodal model with sigmoid loss (variant of CLIP) |
| Pre-training Data | WebLI (English image-text pairs) |
| Input Resolution | 512 x 512 |
about this model
google/siglip-base-patch16-512 is a zero-shot image classification model that uses a sigmoid loss function for language-image pre-training (SigLIP). Unlike standard contrastive learning with softmax normalization, the sigmoid loss operates on individual image-text pairs and does not require a global view of pairwise similarities for normalization. This design simultaneously enables scaling to larger batch sizes while improving performance at smaller batch sizes.
Overview
The model is based on the CLIP architecture but with a more effective loss function introduced by Zhai et al. (2023). It was pre-trained on the English image-text pairs of the WebLI dataset at a resolution of 512×512 pixels. Text inputs are tokenized and padded to 64 tokens; images are normalized across RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5). Training used 16 TPU-v4 chips over three days.
Performance
The paper reports that a related Locked-image Tuning variant (SigLiT), trained with only four TPUv4 chips in two days, achieves 84.5% zero-shot top-1 accuracy on ImageNet. For the standard SigLIP pre-training procedure, a batch size of 32k is sufficient; benefits diminish quickly beyond that, even when scaling to one million.
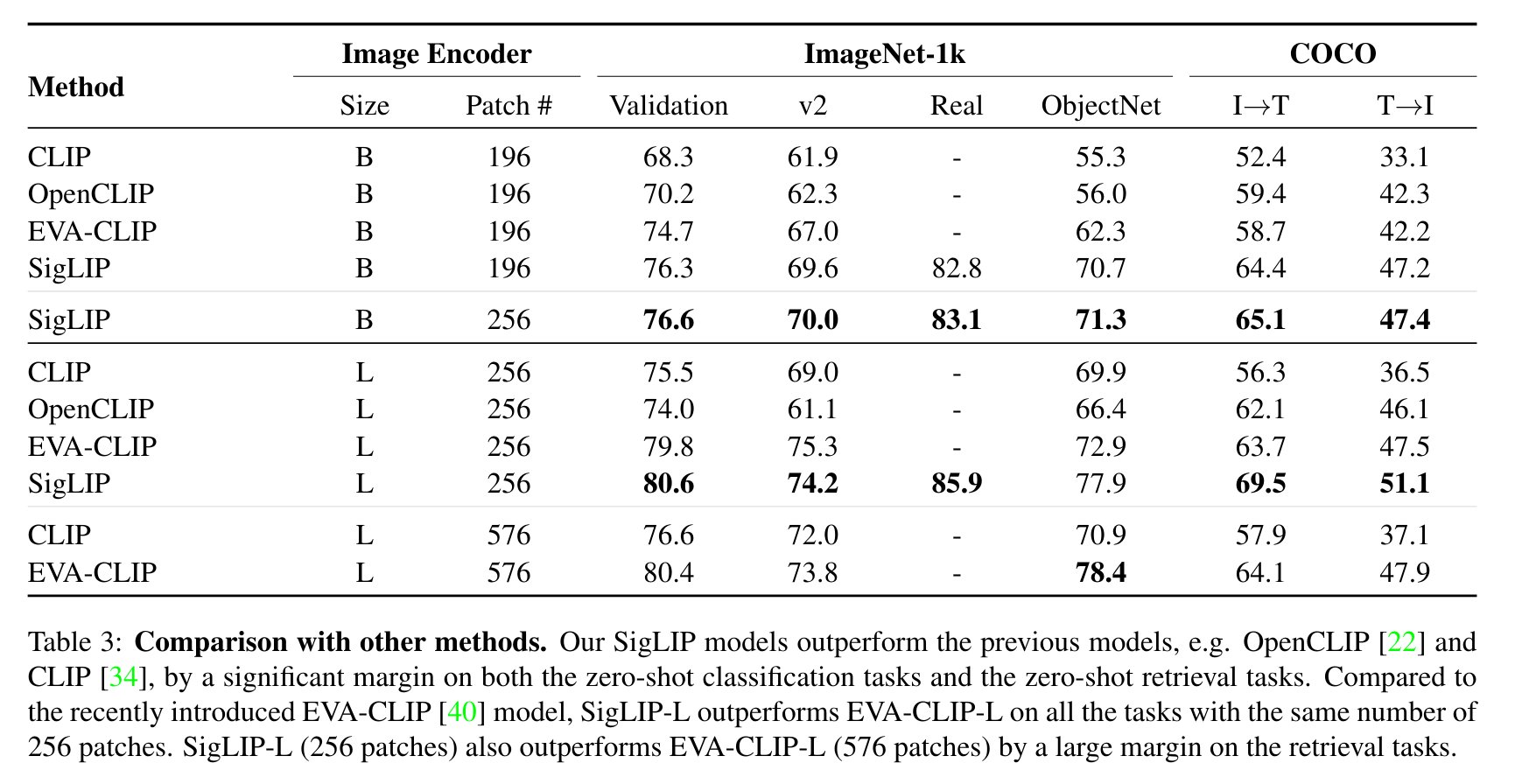
An evaluation comparing SigLIP to CLIP is shown below (source: paper Sigmoid Loss for Language Image Pre-Training).
Architecture Details
The model uses a Vision Transformer (ViT) base-sized patch-16 architecture with 512px input resolution. It is designed for zero-shot image classification and image-text retrieval tasks without requiring task-specific fine-tuning.
best for
- ·Zero-shot classification of images into arbitrary text-defined categories
- ·Image-text retrieval: finding relevant images from text queries or vice versa
- ·Building custom image classifiers without fine-tuning
FAQ
SigLIP uses a pairwise sigmoid loss that does not require global pairwise normalization, allowing larger batch sizes and better performance at smaller batch sizes.
Images should be resized to 512x512 and normalized with mean 0.5 and std 0.5 per channel. Text is tokenized and padded to 64 tokens.
Yes, it supports image-text retrieval by comparing image and text embeddings via the sigmoid logits.
Use the OpenAI-compatible endpoint with your API key, providing an image and candidate labels or text pairs for zero-shot classification or retrieval.
The model card does not specify a license; please refer to the original repository (google-research/big_vision) for terms.
We're benchmarking and onboarding SigLIP Base as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.