SigLIP Base Patch16 256
google/siglip-base-patch16-256
published Jan 2024 · updated Sep 2024
SigLIP Base Patch16 256 is a zero-shot-image model that uses a sigmoid loss function for language-image pre-training, enabling efficient image classification and retrieval without requiring global pairwise similarity normalization.
specs
| Task | Zero-shot image classification, image-text retrieval |
| Architecture | SigLIP (CLIP-like multimodal model with sigmoid loss), base-sized, patch size 16, input resolution 256x256 |
| License | Not specified in model card |
about this model
How it works
Unlike standard contrastive learning with softmax normalization, SigLIP computes a pairwise sigmoid loss on each image-text pair independently. This decouples the loss from batch size, allowing effective training at both small and large batch sizes. The model was pre-trained on the WebLI dataset (English image-text pairs) at 256x256 resolution. Text inputs are tokenized to 64 tokens; images are resized and normalized with mean 0.5 and standard deviation 0.5 per channel.
Training and compute
The model was trained on 16 TPU-v4 chips over three days. The paper demonstrates that a batch size of 32k is sufficient, with diminishing returns up to 1 million. The sigmoid loss simultaneously supports scaling to larger batches and performs better at smaller ones.
Benchmark performance
The underlying approach achieved strong zero-shot results: the SigLiT variant (SigLIP combined with Locked-image Tuning) attained 84.5% top-1 accuracy on ImageNet zero-shot classification, trained on only 4 TPUv4 chips in two days. The evaluation comparison between SigLIP and CLIP from the original paper is shown below.
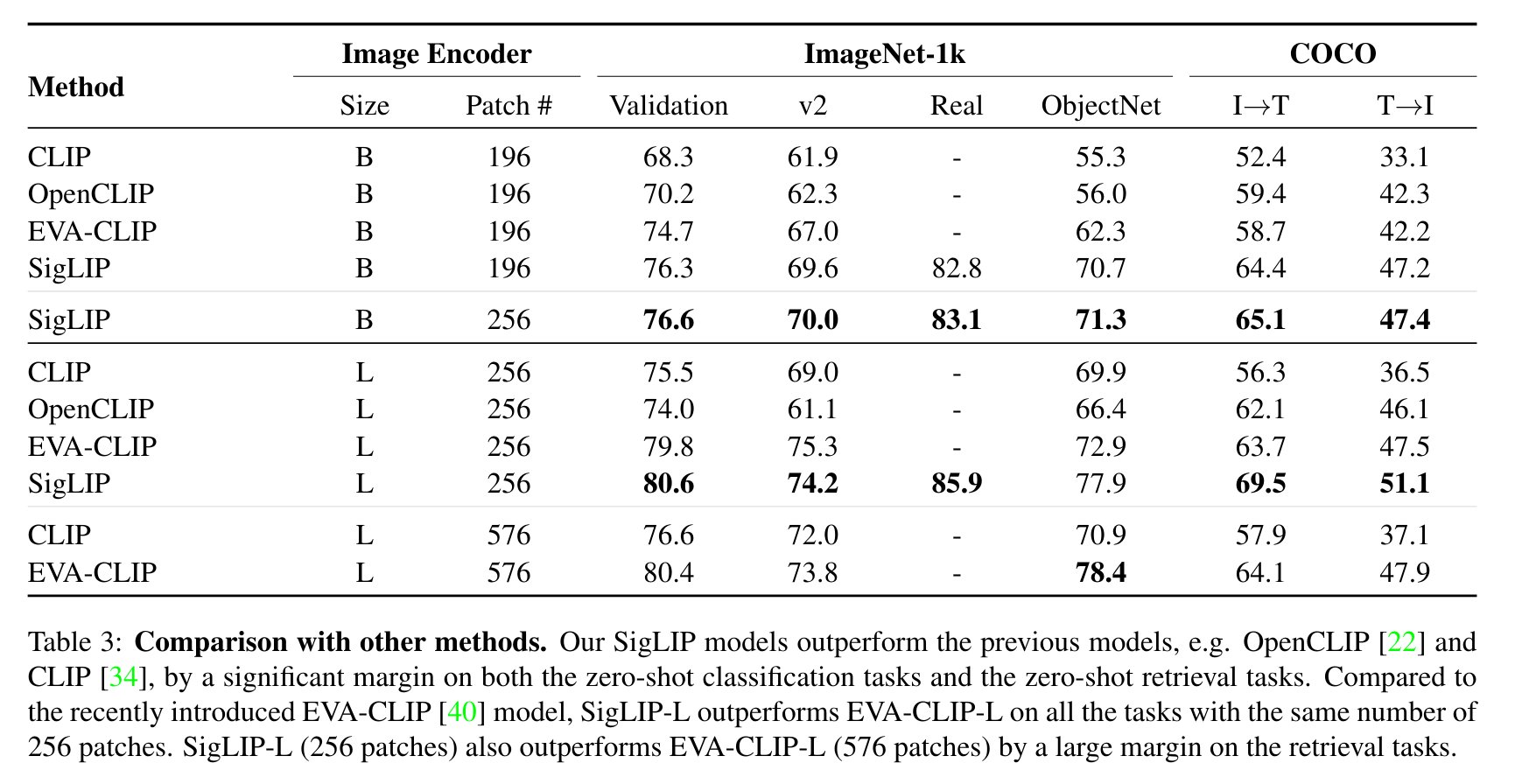
Additional details
The model was presented as an Oral paper at ICCV 2023. It was introduced in Zhai et al., Sigmoid Loss for Language Image Pre-Training (arXiv:2303.15343), and the pre-trained weights are open-sourced via Google Research’s big_vision repository (Apache 2.0 license).
best for
- ·Zero-shot image classification without task-specific training
- ·Image-text retrieval and similarity scoring
FAQ
SigLIP uses a sigmoid loss that operates on individual image-text pairs, removing the need for global pairwise similarity normalization. This allows scaling to larger batch sizes and performs better at smaller batch sizes compared to CLIP.
Images are resized to 256x256 pixels and normalized with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5). Text is tokenized and padded to 64 tokens.
Use the gigarouter OpenAI-compatible endpoint with your API key. Send an image URL or base64-encoded image along with candidate text labels to perform zero-shot classification.
The model card does not specify a license. The associated big_vision repository typically uses Apache 2.0, but this is not confirmed for the model itself.
The model card does not specify the batch size used for this model. The paper recommends a batch size of 32k as sufficient for SigLIP training.
We're benchmarking and onboarding SigLIP Base Patch16 256 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.