Nougat Small
facebook/nougat-small
published Sep 2023 · updated Nov 2023
Nougat Small is an image-to-text model that transcribes scientific PDFs into Markdown format.
specs
| Task | Image-to-Text (PDF to Markdown) |
| Architecture | Swin Transformer encoder + mBART decoder |
| Model Version | 0.1.0-small |
| Output Format | Markdown (.mmd) |
about this model
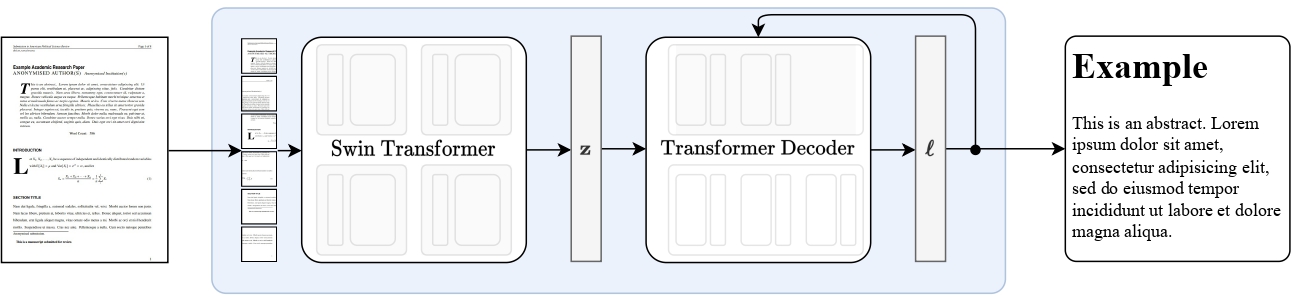
Nougat-small is an image-to-text model that transcribes scientific PDF page images into Markdown, including LaTeX math and tables. It is a Donut model with a Swin Transformer vision encoder and an mBART text decoder, trained autoregressively to predict the markup directly from pixel inputs. The model was introduced in the paper Nougat: Neural Optical Understanding for Academic Documents (Blecher et al., 2023).
Key strengths include accurate recognition of complex mathematical expressions and table structures, addressing the semantic information loss common in PDF conversion. The model outputs .mmd files (Mathpix Markdown compatible) and includes a failure detection heuristic that produces [MISSING_PAGE] responses when a page cannot be reliably transcribed.
As a specialist model hosted on Gigarouter, Nougat-small is available via an OpenAI-compatible API requiring no local installation or GPU management. The underlying architecture is designed for academic document understanding, making it suitable for converting scanned papers, textbooks, and technical reports into machine-readable text.
best for
- ·Converting academic PDFs to Markdown with LaTeX math and tables
- ·Extracting machine-readable text from scanned scientific papers
- ·Automating arXiv paper ingestion for knowledge bases
FAQ
Nougat Small is a lightweight image-to-text model for converting PDF pages (as images) into Markdown, designed for scientific documents.
Input: pixels of PDF pages. Output: Markdown text (saved as .mmd files with LaTeX math and tables).
This is the 0.1.0-small version, lighter and faster. A larger 0.1.0-base version is also available with potentially higher accuracy.
Use the gigarouter OpenAI-compatible endpoint with an API key, passing PDF images as input.
Yes, it produces [MISSING_PAGE] for failures; this heuristic can be disabled via the --no-skipping flag.
We're benchmarking and onboarding Nougat Small as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.