PE-Core L14 336
facebook/PE-Core-L14-336
published Apr 2025 · updated Apr 2025
PE-Core L14 336 is a zero-shot image model that performs image and video understanding via contrastive vision-language learning.
specs
| Task | Zero-Shot Image & Video Classification & Retrieval |
| Architecture | Vision Transformer (ViT) L/14 with attention pooling, 336px input resolution |
| Parameters | 0.63B total (0.32B vision, 0.31B text) |
| License | Apache 2.0 |
| Input Resolution | 336px |
about this model
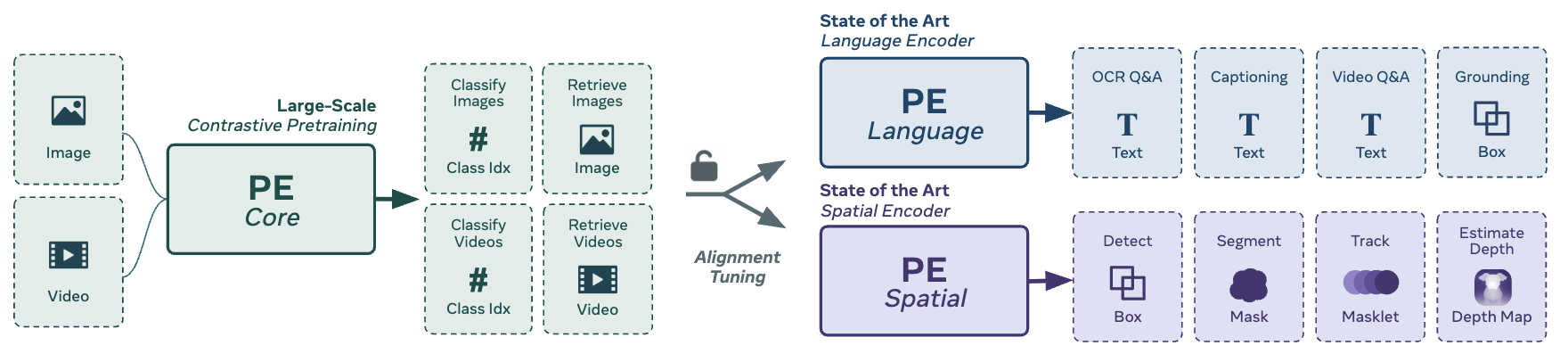
facebook/PE-Core-L14-336 is a zero-shot image classification and retrieval model that produces state-of-the-art visual embeddings for open-vocabulary recognition tasks. It is a member of Meta’s Perception Encoder (PE) family, trained with a robust contrastive vision-language pretraining recipe and then refined on synthetically aligned video data. Unlike traditional encoders that rely on task-specific objectives, PE extracts strong general-purpose features from intermediate network layers via language and spatial alignment methods, enabling competitive performance across classification, retrieval, and downstream dense prediction tasks.
Key Strengths
- Zero-shot classification and retrieval – excels on standard and challenging benchmarks, particularly ImageNet-A and ObjectNet.
- High-resolution input – processes 336 × 336 pixel images with a Vision Transformer L/14 architecture (304M vision parameters, 614M total).
- Broad zero-shot transfer – achieves strong results on both image (IN-1k, IN-v2, IN-A, ObjectNet) and cross-modal retrieval (COCO-T2I, VTT-T2I).
- Apache 2.0 license – open for both research and commercial use.
Benchmark Performance
The table below reports top-1 accuracy for zero-shot image classification and recall@1 (text-to-image) for retrieval tasks.
| Model | IN-1k | IN-v2 | IN-A | ObjectNet | COCO-T2I | Kinetics-400 | VTT-T2I |
|---|---|---|---|---|---|---|---|
| L/14 336px | 83.5 | 77.9 | 89.0 | 84.7 | 57.1 | 73.4 | 50.3 |
The model is especially effective on hard distributions: it achieves 89.0% on ImageNet-A (natural adversarial examples) and 84.7% on ObjectNet (controlled object rotation and background).
As a hosted API on gigarouter, this model is available via an OpenAI-compatible endpoint with no infrastructure setup required.
best for
- ·Zero-shot image classification on hard benchmarks like ImageNet-A and ObjectNet
- ·Zero-shot image-to-text retrieval (e.g., COCO T2I)
- ·Zero-shot video classification (e.g., Kinetics-400)
FAQ
It is a state-of-the-art vision encoder from Meta that produces strong general visual embeddings for zero-shot classification, retrieval, and video understanding via contrastive learning.
It outperforms existing models on zero-shot ImageNet robustness (86.6 average) and video classification (76.9% on Kinetics-400) while also setting new COCO detection records.
Both the model and code are licensed under Apache 2.0, as indicated in the official GitHub repository.
It expects images (resized to 336x336 pixels) and text tokens (up to 32 tokens for the text encoder). The vision tower outputs 1024-dimensional features after attention pooling.
Use the OpenAI-compatible endpoint with your API key. Send image and text data as specified in the gigarouter documentation for zero-shot image models.
We're benchmarking and onboarding PE-Core L14 336 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.