EBind Full
encord-team/ebind-full
published Nov 2025 · updated Nov 2025
EBind Full is a multimodal embedding model that projects image, video, audio, text, and 3D point clouds into a shared embedding space for cross-modal similarity computations.
specs
| Task | Multimodal Embedding |
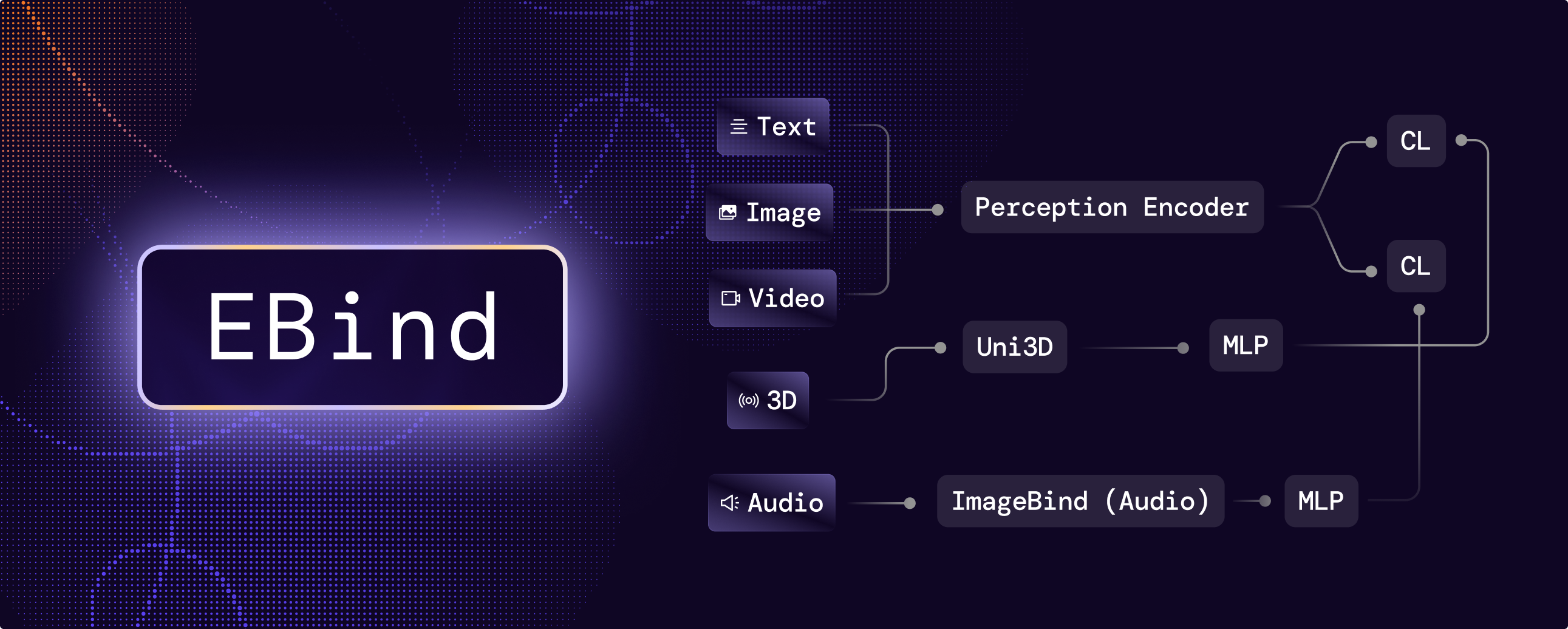
| Architecture | Ensemble of Perception Encoder, ImageBind, and Uni3D |
| Parameters | 1.8 billion |
| Embedding Size | 1024 |
| License | CC-BY-NC-SA 4.0 |
about this model
EBind is a multi-modal embedding model that projects image, video, audio, text, and 3D point cloud inputs into a shared 1024-dimensional embedding space for cross-modal similarity computation. It builds on three foundation models: the Perception Encoder, ImageBind, and Uni3D. Audio and 3D point cloud embeddings are projected via MLPs into the Perception Encoder's embedding space, producing unit-norm embeddings directly usable for cosine similarity comparisons.
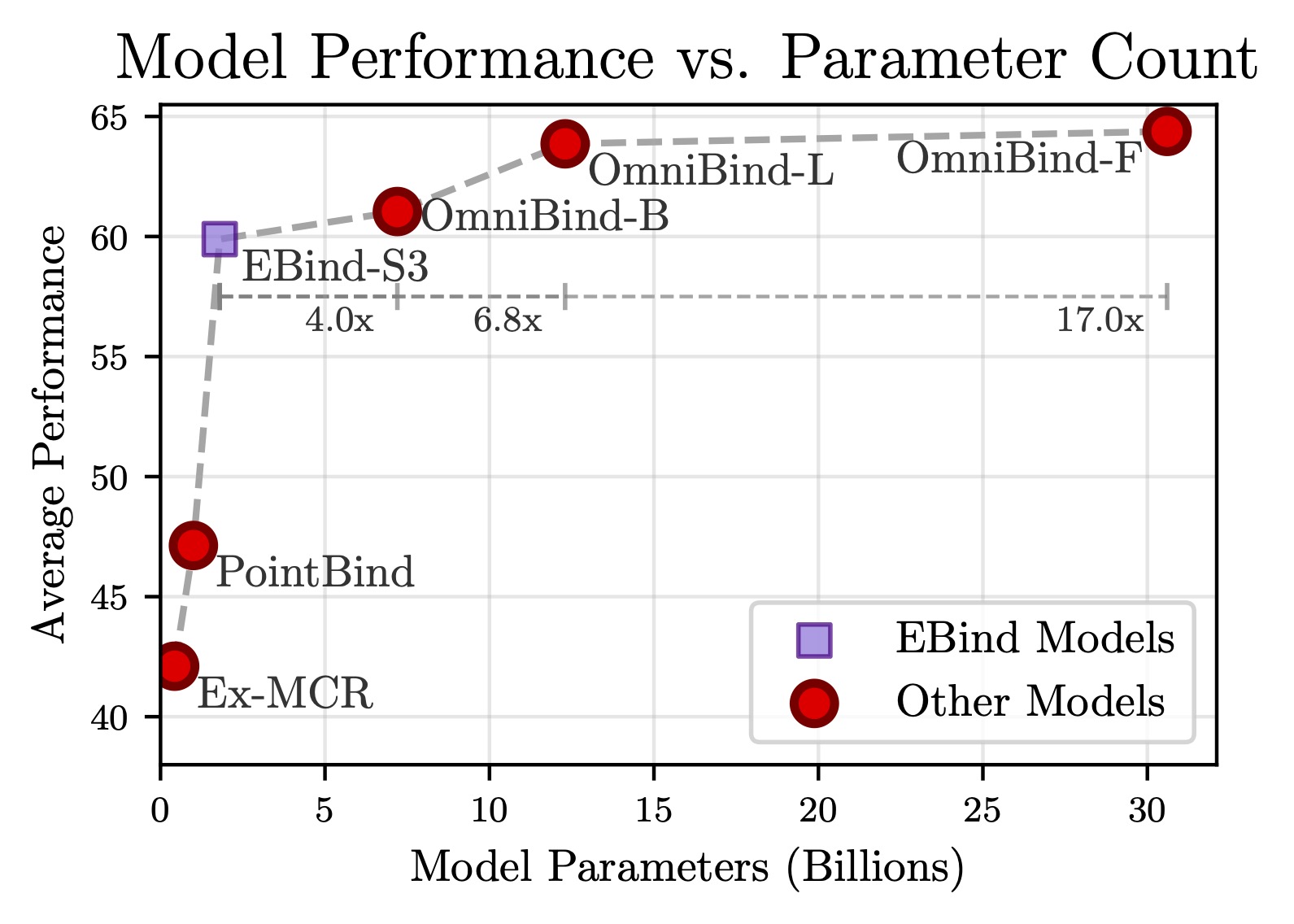
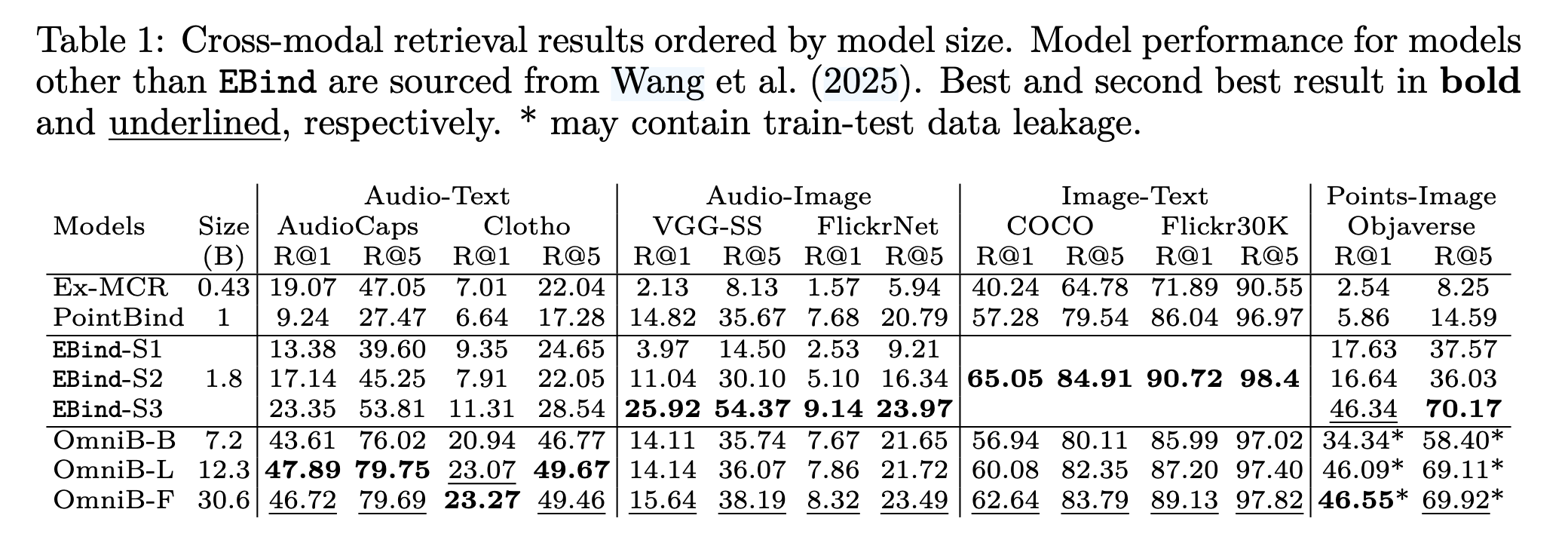
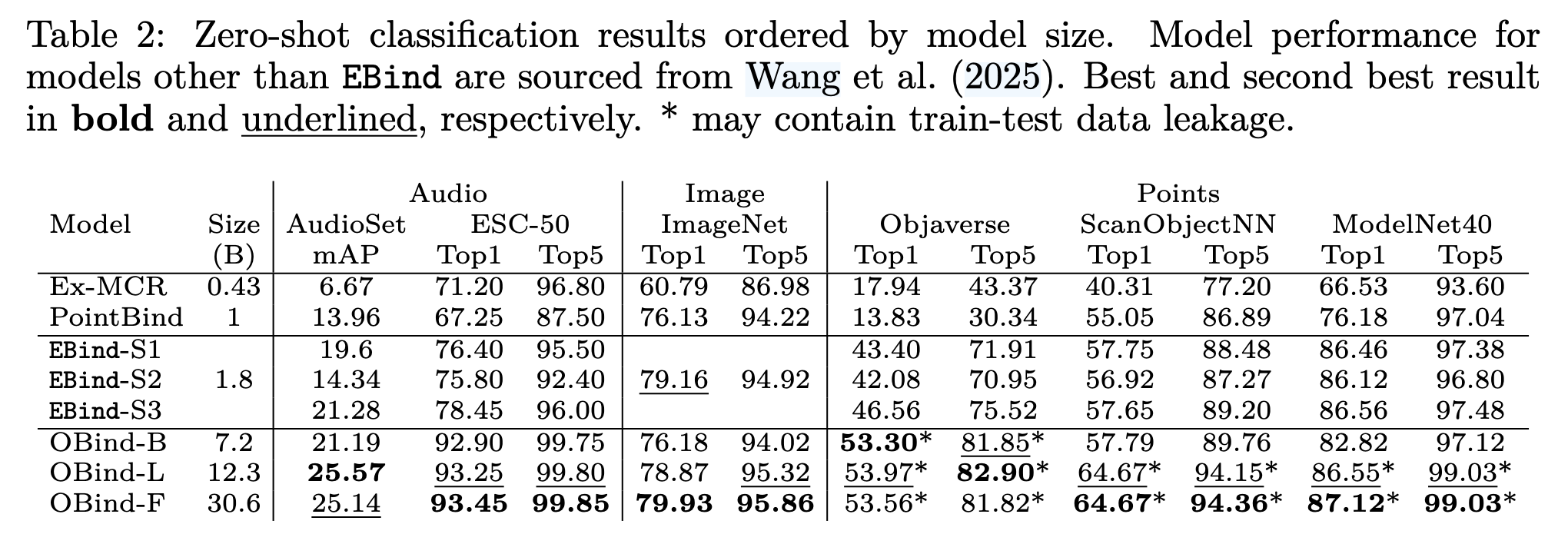
The model achieves strong performance despite its compact 1.8B-parameter size, outperforming models 4 to 17 times larger across 13 benchmarks. This efficiency is enabled by a carefully curated dataset combining 6.7M fully-automated multimodal quintuples, 1M semi-automated human-annotated triples, and 3.4M pre-existing captioned items. Training requires only a single GPU in hours rather than days.
Key strengths include:
- Supports five modalities (image, video, audio, text, 3D point clouds) in a single model.
- Outperforms models 4 to 17 times larger on 13 benchmarks, including retrieval and zero-shot classification tasks.
- Trainable on a single GPU in hours, not days.
- Produces unit-norm embeddings for direct cosine similarity computation.
The model is published under the CC-BY-NC-SA 4.0 license. For further details, see the GitHub repository and the paper.
best for
- ·Cross-modal similarity search (e.g., find images matching audio)
- ·Zero-shot classification across modalities
- ·Multimodal content understanding for retrieval and generation
FAQ
It supports image, video, audio, text, and 3D point clouds.
The model produces 1024-dimensional unit-norm embeddings.
EBind Full has approximately 1.8 billion parameters.
It is released under the CC-BY-NC-SA 4.0 license.
Send requests to the OpenAI-compatible endpoint with your API key; see gigarouter documentation for details.
We're benchmarking and onboarding EBind Full as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.