Ornith 1.0 35B
deepreinforce-ai/Ornith-1.0-35B
published Jun 2026 · updated Jun 2026
Ornith 1.0 35B is a text-generation model for agentic coding that uses a self-improving reinforcement learning framework to jointly optimize scaffold and solution rollouts.
specs
| Task | Text Generation (Agentic Coding) |
| Architecture | Mixture of Experts (MoE) |
| Parameters | 35B |
| License | MIT |
about this model
Self-Improving Training Framework
The model employs a two-stage RL process: it first proposes a refined scaffold conditioned on the task and previously used scaffold, then generates a solution rollout conditioned on that scaffold and task description. Reward from the rollout is propagated to both stages, enabling the model to discover better search trajectories and generate higher-quality solutions. A three-layer reward hacking defense protects training integrity through an immutable outer trust boundary, deterministic monitoring of forbidden actions, and a frozen LLM judge for intent-level gaming detection.
Benchmark Performance
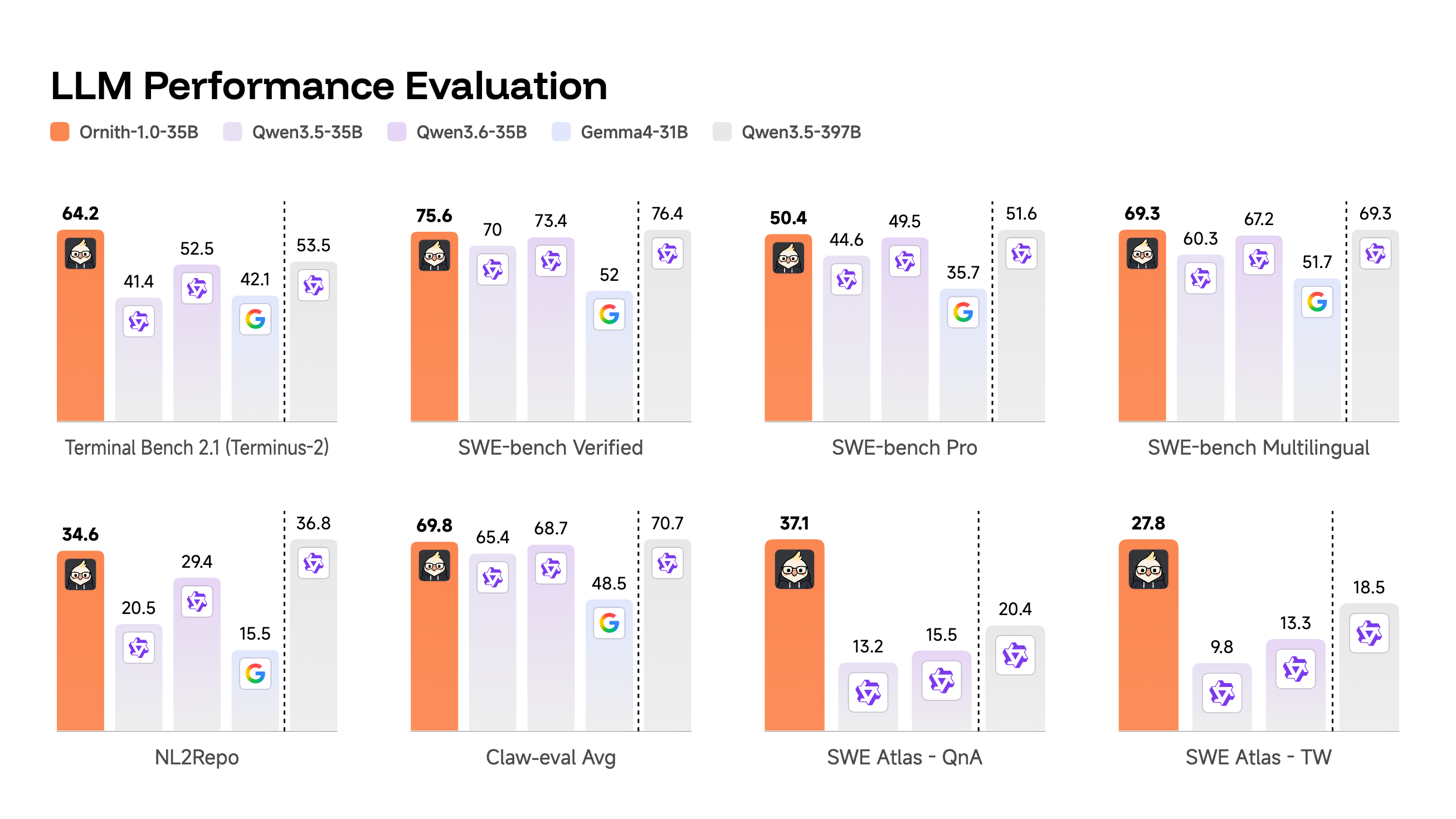
Ornith-1.0-35B achieves state-of-the-art results among open-source models of comparable size on agentic coding benchmarks:
| Benchmark | Ornith-1.0-35B | Qwen3.5-35B | Qwen3.6-35B | Gemma4-31B | Qwen3.5-397B |
|---|---|---|---|---|---|
| Terminal-Bench 2.1 (Terminus-2) | 64.2 | 41.4 | 52.5 | 42.1 | 53.5 |
| Terminal-Bench 2.1 (Claude Code) | 62.8 | 38.9 | 49.2 | - | 48.6 |
| SWE-bench Verified | 75.6 | 70 | 73.4 | 52 | 76.4 |
| SWE-bench Pro | 50.4 | 44.6 | 49.5 | 35.7 | 51.6 |
| SWE-bench Multilingual | 69.3 | 60.3 | 67.2 | 51.7 | 69.3 |
| NL2Repo | 34.6 | 20.5 | 29.4 | 15.5 | 36.8 |
| Claw-eval Avg | 69.8 | 65.4 | 68.7 | 48.5 | 70.7 |
| SWE Atlas - QnA | 37.1 | 13.2 | 15.5 | - | 20.4 |
| SWE Atlas - RF | 29.7 | 10.2 | 11.4 | - | 18.4 |
| SWE Atlas - TW | 27.8 | 9.8 | 13.3 | - | 18.5 |
The 35B model surpasses Qwen 3.5-397B (53.5) on Terminal-Bench 2.1 despite having roughly one-tenth the parameters. The larger Ornith-1.0-397B variant achieves 77.5 on Terminal-Bench 2.1 and 82.4 on SWE-Bench Verified.

The model uses a structured tool-calling format with <tool_call> XML tags and nested <function=...> blocks. It is a reasoning model that opens assistant turns with a <think>...</think> block. Released under the MIT license.
best for
- ·Automated software engineering tasks like fixing bugs and implementing features in code repositories
- ·Terminal-based coding agents that need to navigate and edit codebases autonomously
FAQ
It is designed for agentic coding tasks such as automated bug fixing, feature implementation, and repository-level code generation, achieving state-of-the-art results on benchmarks like SWE-Bench and Terminal-Bench.
It is MIT licensed, globally accessible, and free from regional limitations.
Despite having only 35B parameters, Ornith 1.0 35B surpasses Qwen 3.5-397B on Terminal-Bench 2.1 (64.2 vs 53.5) and achieves competitive results on SWE-Bench Verified (75.6 vs 76.4).
Use the gigarouter OpenAI-compatible endpoint with your API key. The model is a reasoning model that outputs a <think> block before the final answer.
We're benchmarking and onboarding Ornith 1.0 35B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.