VLM2Vec LoRA
TIGER-Lab/VLM2Vec-LoRA
published Oct 2024 · updated Jul 2025
VLM2Vec LoRA is a multimodal embedding model that converts a vision-language model (Phi-3.5-V) into a universal embedding model via contrastive training on the MMEB benchmark.
specs
| Task | Multimodal Embedding |
| Architecture | Phi-3.5-V with LoRA adapters |
| Pooling | Last token |
| Normalization | Yes |
| Training Data | MMEB-train (20 datasets) |
about this model
VLM2Vec is a multimodal embedding model that converts a vision-language model (Phi-3.5-V) into a unified embedding model capable of processing any combination of images and text to generate a fixed-dimensional vector based on task instructions. It is designed for massive multimodal embedding tasks including classification, visual question answering, multimodal retrieval, and visual grounding.
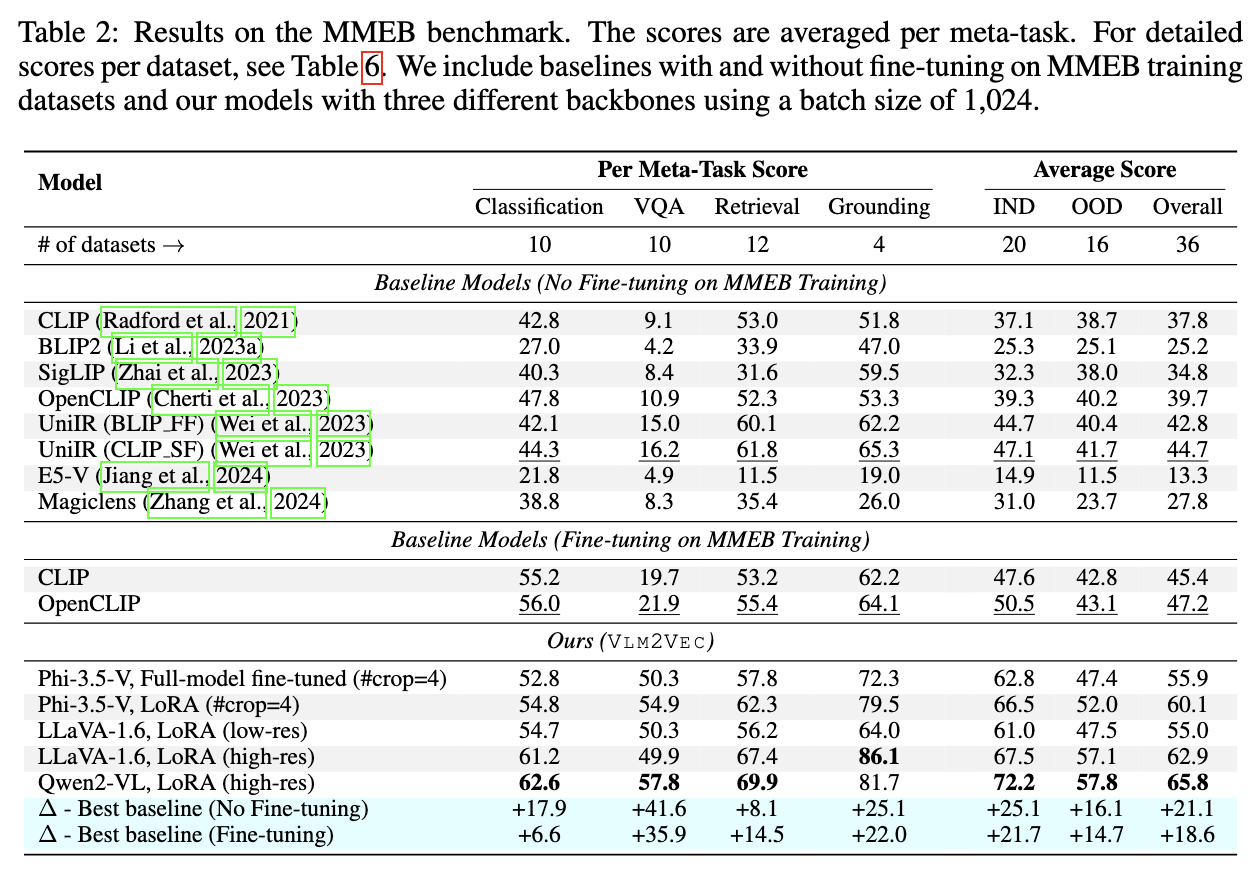
The model is trained on the MMEB benchmark (20 training datasets) using contrastive learning with in-batch negatives and GradCache to increase effective batch size. It is evaluated on 16 MMEB evaluation datasets covering both in-distribution and out-of-distribution tasks. VLM2Vec achieves an absolute average improvement of 10% to 20% over existing multimodal embedding models across all MMEB evaluation datasets.
The model processes any combination of images and text to generate a fixed-dimensional vector based on task instructions, using an [EOS] token as the representation of multimodal inputs. Unlike CLIP or BLIP, which encode text or images independently, VLM2Vec can follow task instructions to produce task-specific embeddings.
The VLM2Vec project has evolved through multiple versions. The V2.0 checkpoint (Apache-2.0 licensed) uses the Qwen2VL architecture. The MMEB benchmark has been extended to MMEB-V3, which covers 190 tasks including audio tasks (classification, cross-modal retrieval, temporal grounding), text retrieval (instruction-following, reasoning, long-context, multi-condition), and agent tasks (tool retrieval, GUI control, agent memory retrieval). MMEB-V3 also introduces OmniSET (Omni-modality Semantic Equivalence Tuples) for controlled analysis of modality effects and instruction-conditioned cross-modal retrieval behavior.
best for
- ·Multimodal retrieval: finding images that match a text description or vice versa
- ·Visual question answering via embedding similarity
- ·Image-text semantic similarity and clustering
FAQ
It is a lightweight LoRA-tuned version of VLM2Vec based on Phi-3.5-V, trained on MMEB-train to produce universal multimodal embeddings.
It accepts any combination of text and images; the input is a task instruction followed by image tokens and text.
Use the OpenAI-compatible endpoint with your API key; send text and image data as specified in the API documentation.
VLM2Vec achieves 10-20% absolute improvement over existing multimodal embedding models on the MMEB benchmark across 36 datasets.
It covers four meta-tasks: classification, visual question answering, multimodal retrieval, and visual grounding, evaluated on 16 datasets.
We're benchmarking and onboarding VLM2Vec LoRA as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.