Qwen3 ASR 0.6B
Qwen/Qwen3-ASR-0.6B
published Jan 2026 · updated Jan 2026
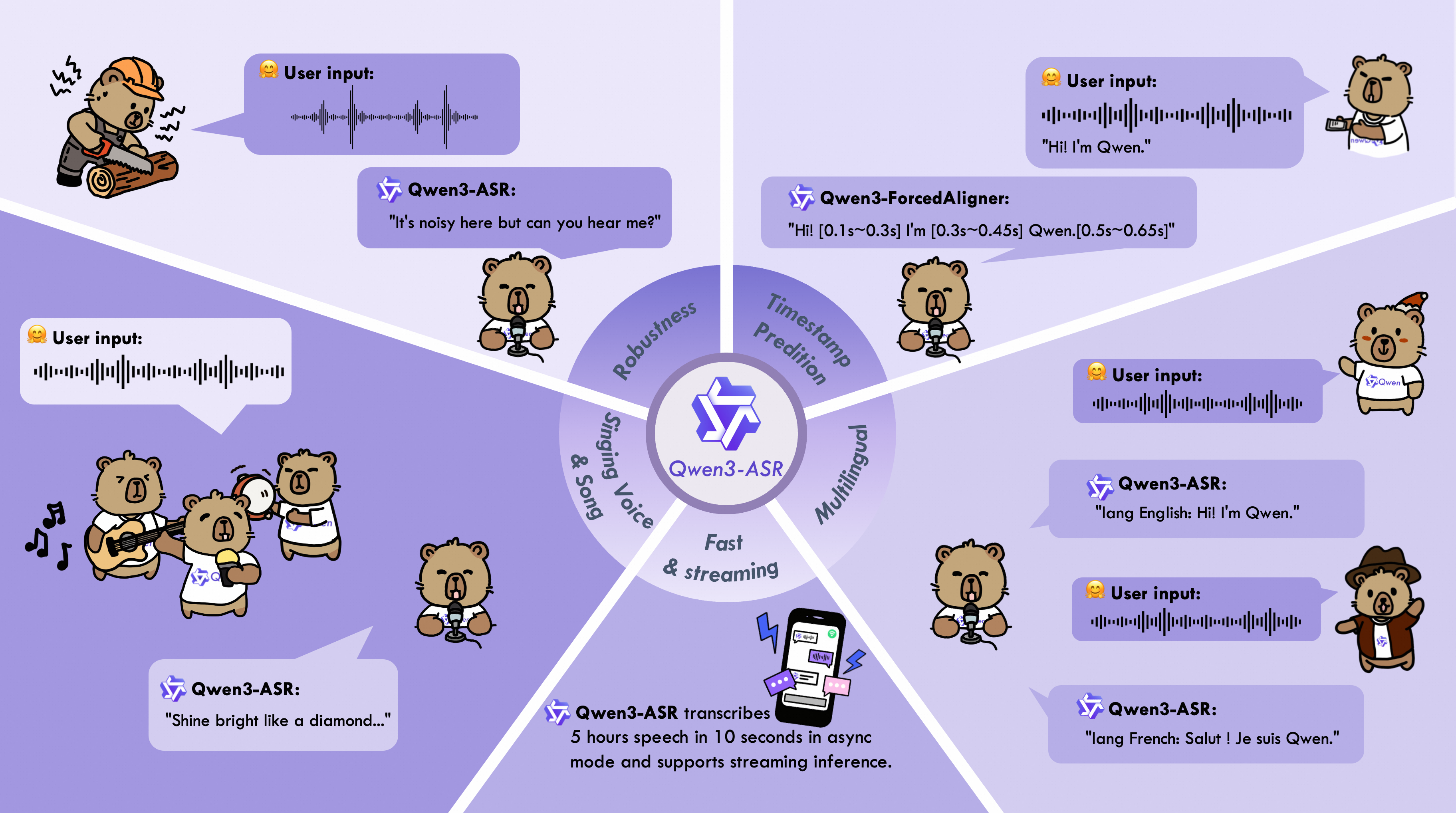
Qwen3 ASR 0.6B is an all-in-one automatic speech recognition model that supports language identification and transcription for 52 languages and dialects.
specs
| Task | Automatic Speech Recognition (ASR) and Language Identification |
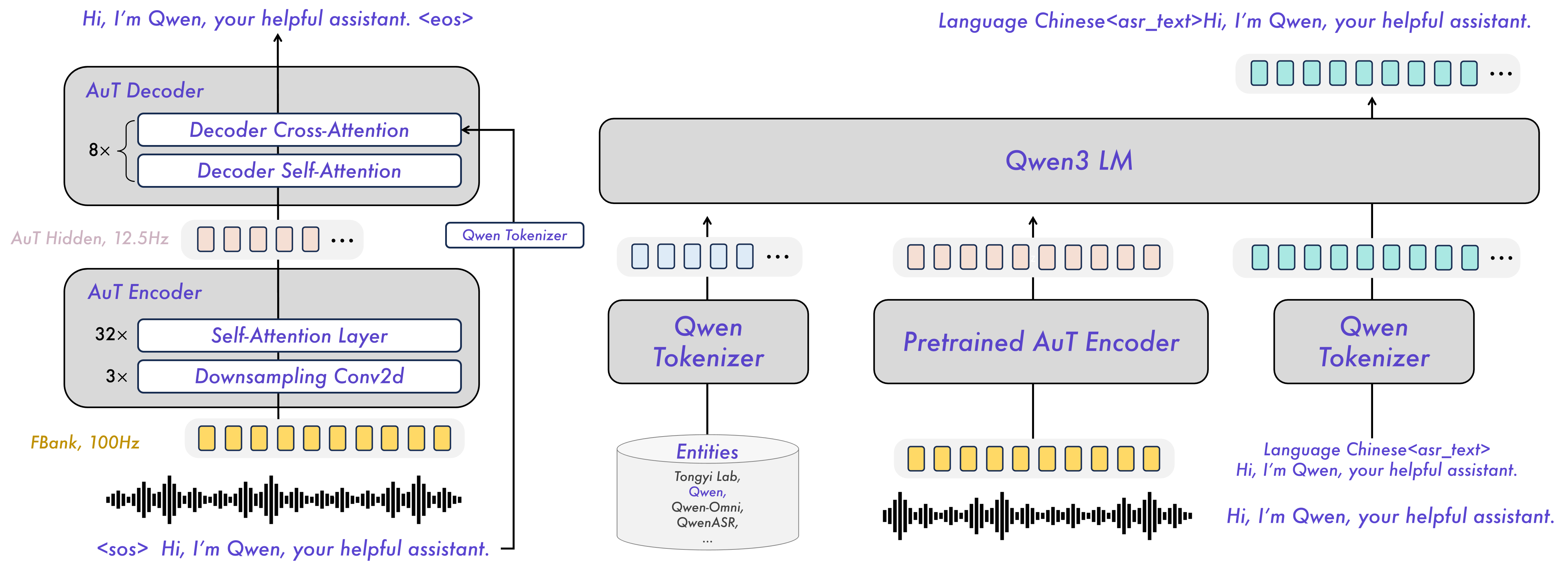
| Architecture | Based on Qwen3-Omni foundation model |
| Parameters | 0.6B |
| License | Apache 2.0 |
about this model
Qwen3-ASR-0.6B is a speech recognition model that performs automatic speech recognition (ASR) and language identification across 52 languages and dialects. Built on the Qwen3-Omni foundation and trained on large-scale speech data, it is designed to deliver high-quality recognition in complex acoustic environments while maintaining low latency.
Capabilities
- All-in-one recognition: Supports 30 languages (e.g., English, Chinese, Arabic, Japanese, Korean, French) and 22 Chinese dialects (e.g., Cantonese, Sichuan, Minnan), including English accents from multiple regions. Accepts speech, singing voice, and songs with background music.
- Streaming and offline inference: A single model handles both modes and can transcribe long audio segments without segmentation.
- Forced alignment: The companion Qwen3-ForcedAligner-0.6B provides word-level timestamps for up to 5 minutes of speech in 11 languages, with accuracy surpassing existing end-to-end forced alignment models.
Performance
The 0.6B version optimizes for accuracy and efficiency. Key metrics (from the Qwen3-ASR technical report):
- Average time-to-first-token (TTFT) as low as 92 ms.
- Throughput of 2000× at a concurrency of 128, transcribing 2000 seconds of speech in one second.
- Offers the best accuracy-efficiency trade-off among open-source ASR models.
Supported Languages and Dialects
| Model | Supported Languages | Supported Dialects | Inference Mode | Audio Types |
|---|---|---|---|---|
| Qwen3-ASR-0.6B | Chinese, English, Cantonese, Arabic, German, French, Spanish, Portuguese, Indonesian, Italian, Korean, Russian, Thai, Vietnamese, Japanese, Turkish, Hindi, Malay, Dutch, Swedish, Danish, Finnish, Polish, Czech, Filipino, Persian, Greek, Hungarian, Macedonian, Romanian | Anhui, Dongbei, Fujian, Gansu, Guizhou, Hebei, Henan, Hubei, Hunan, Jiangxi, Ningxia, Shandong, Shaanxi, Shanxi, Sichuan, Tianjin, Yunnan, Zhejiang, Cantonese (Hong Kong accent), Cantonese (Guangdong accent), Wu language, Minnan language | Offline / Streaming | Speech, Singing Voice, Songs with BGM |
Released under the Apache 2.0 license. Gigarouter hosts this model as a managed, OpenAI-compatible API — no local setup required.
best for
- ·Real-time multilingual speech transcription with language identification
- ·High-throughput batch transcription of short audio clips
- ·Streaming ASR for live captioning or voice assistants
FAQ
It supports 30 languages and 22 Chinese dialects, including English, Chinese, Arabic, German, French, Spanish, and many more.
It is released under the Apache 2.0 license.
It achieves an average time-to-first-token as low as 92ms and can transcribe 2000 seconds of speech in 1 second at a concurrency of 128.
Yes, it supports streaming inference via the vLLM backend.
Use the gigarouter OpenAI-compatible endpoint with your API key, sending audio as a URL or base64 data in a chat completion request.
We're benchmarking and onboarding Qwen3 ASR 0.6B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.