PP-DocLayout Plus L
PaddlePaddle/PP-DocLayout_plus-L
published Jun 2025 · updated Jul 2025
PP-DocLayout Plus L is an image-to-text model that performs layout area localization on document images, detecting 20 common layout categories such as titles, text, tables, and figures.
specs
| Task | Layout Detection |
| Architecture | RT-DETR-L |
| mAP (0.5) | 83.2% |
| License | Apache 2.0 |
about this model
PP-DocLayout_plus-L is an image-to-text layout detection model that identifies and localizes 20 common document layout elements with high precision. It is trained on a self-built dataset covering Chinese and English papers, PPT, multi-layout magazines, contracts, books, exams, ancient books, and research reports using the RT-DETR-L architecture. The detected categories include: document title, paragraph title, text, page number, abstract, table, references, footnotes, header, footer, algorithm, formula, formula number, image, table, seal, figure_title, chart, sidebar text, and lists of references.
Benchmark Performance
| Model | mAP(0.5) (%) |
|---|---|
| PP-DocLayout_plus-L | 83.2 |
The evaluation set comprises 1,000 document-type images, including Chinese and English papers, magazines, newspapers, research reports, PPT, test papers, and textbooks.
Visualization Example
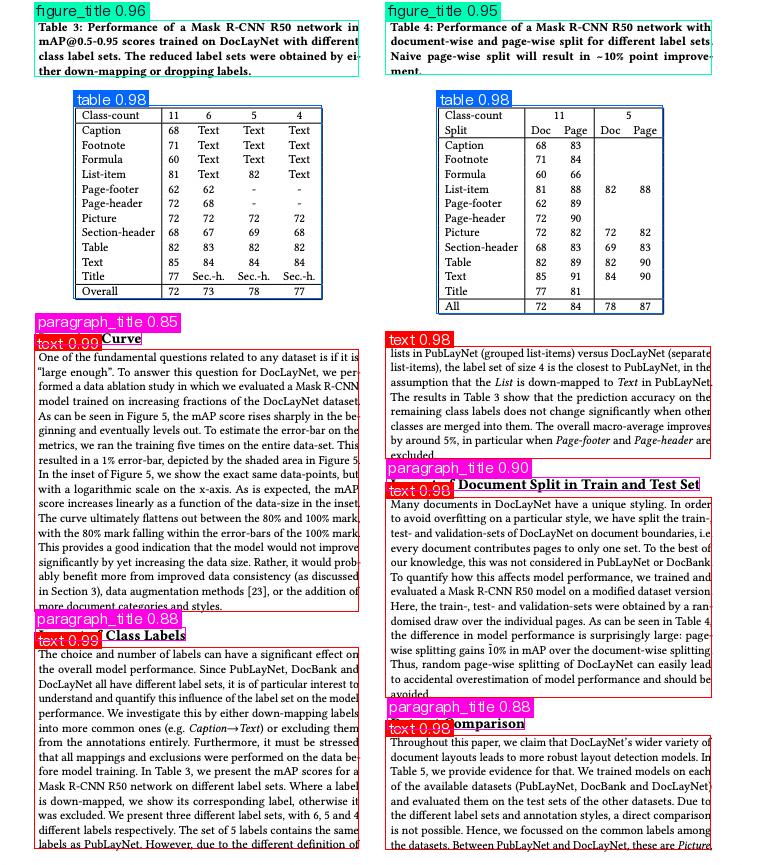
Additional Details
- Licensed under Apache 2.0.
- Supports CPU, GPU, XPU, and NPU hardware across Linux, Windows, and macOS.
- Used as the default layout detection model in the PP-StructureV3 pipeline for structured document extraction.
- Adopted by 6,000+ repositories on GitHub.
best for
- ·Document layout analysis and region classification
- ·Extracting structured information from scanned documents
- ·Preprocessing for OCR and document understanding pipelines
FAQ
It is built on RT-DETR-L and trained on a self-built dataset with 20 layout categories, achieving 83.2% mAP on the evaluation set.
It accepts document images as input and outputs bounding boxes with class labels and confidence scores for each detected layout region.
Use the gigarouter OpenAI-compatible endpoint with your API key, sending an image URL or base64-encoded image.
The model is released under the Apache 2.0 license, allowing free use, modification, and distribution.
It supports CPU, GPU, XPU, and NPU inference, and runs on Linux, Windows, and macOS.
We're benchmarking and onboarding PP-DocLayout Plus L as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.