PP-DocLayoutV3
PaddlePaddle/PP-DocLayoutV3
published Jan 2026 · updated Jun 2026
PP-DocLayoutV3 is a segmentation model for document layout analysis that predicts multi-point bounding boxes and logical reading orders for non-planar document images.
specs
| Task | Document Layout Analysis (Segmentation) |
| Input | Document image |
| Output | Multi-point bounding boxes and logical reading order |
| License | Apache 2.0 |
about this model
PP-DocLayoutV3 is a layout analysis segmentation model designed for non-planar document images. Unlike conventional approaches that predict axis-aligned bounding boxes, it directly outputs multi-point bounding boxes for layout elements and determines logical reading orders for skewed, curved, and warped surfaces—all in a single forward pass, reducing cascading errors.
The model is a core component of PaddleOCR-VL-1.5, which achieves a state-of-the-art accuracy of 94.5% on the OmniDocBench v1.5 benchmark. It also attains SOTA performance on the newly introduced Real5-OmniDocBench benchmark, which evaluates robustness against real-world physical distortions including scanning, skew, warping, screen-photography, and illumination. This work has been accepted to ECCV 2026.
Model Architecture
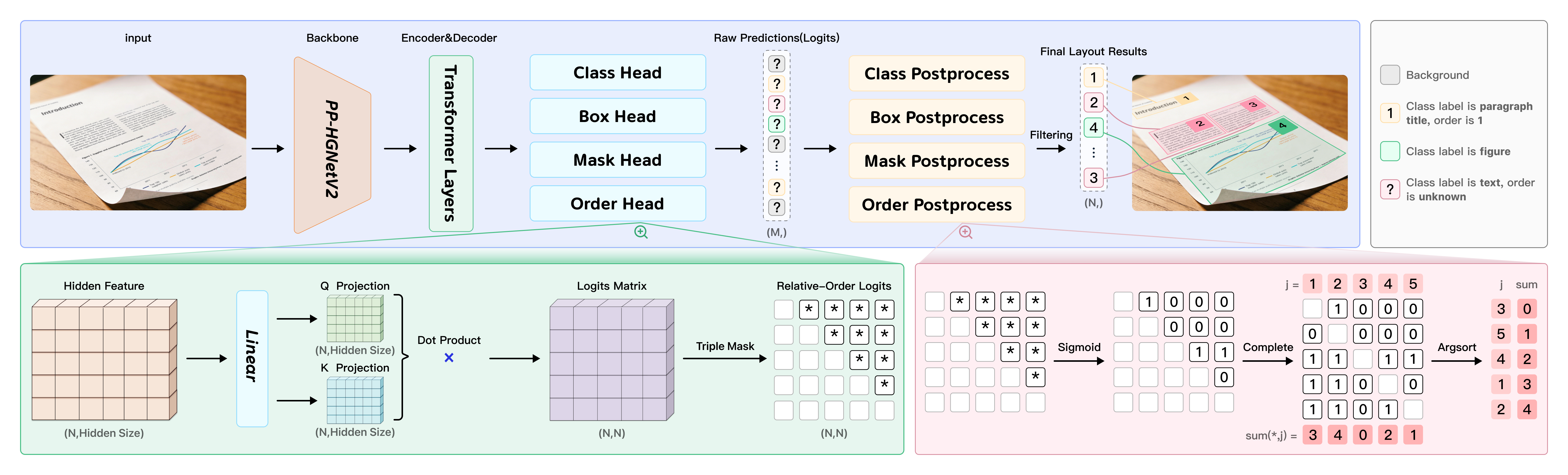
Visualization of Robustness
The following images illustrate the model's performance under various challenging conditions:
| Condition | Example Output |
|---|---|
| Light Variation |  |
| Skewing |  |
| Screen-photo |  |
| Curving |  |
best for
- ·Parsing non-planar documents (skewed, curved, illuminated)
- ·Layout analysis for OCR pipelines
- ·Real-world document processing with physical distortions
FAQ
It is best for analyzing layouts on non-planar document images, such as skewed, curved, or poorly lit documents.
The PaddleOCR-VL-1.5 pipeline, which includes PP-DocLayoutV3, achieves 94.5% SOTA accuracy on OmniDocBench v1.5.
Input is a document image; output includes multi-point bounding boxes for layout elements and their logical reading order.
Use the gigarouter OpenAI-compatible endpoint with an API key.
Apache 2.0.
We're benchmarking and onboarding PP-DocLayoutV3 as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.