LFM2.5-230M
LiquidAI/LFM2.5-230M
published Jun 2026 · updated Jun 2026
LFM2.5-230M is a compact, instruction-tuned text-generation model optimized for on-device deployment and agentic tasks.
specs
| Task | Text Generation |
| Architecture | Hybrid (8 double-gated LIV convolution blocks + 6 GQA blocks) |
| Parameters | 230M |
| License | Not specified in the card |
about this model
LFM2.5-230M is a text-generation model optimized for on-device deployment, hosted on gigarouter as an OpenAI-compatible API. It combines a hybrid architecture of convolution and attention layers with 230 million parameters and was trained on 19 trillion tokens. The model supports a 32,768-token context window across ten languages: English, Arabic, Chinese, French, German, Italian, Japanese, Korean, Portuguese, and Spanish. It underwent a three-stage post-training pipeline—supervised fine-tuning with distillation from LFM2.5-350M, direct preference optimization, and multi-domain reinforcement learning—making it well-suited for agentic tasks such as tool use and structured data extraction.
Key strengths
- Fast on-device inference: 213 tokens/second on a Galaxy S25 Ultra and 42 tokens/second on a Raspberry Pi 5, with a small memory footprint.
- Native function-calling support using a ChatML-like template, enabling straightforward integration into agentic pipelines.
- Day-one support for multiple inference frameworks including llama.cpp, MLX, vLLM, SGLang, and ONNX.
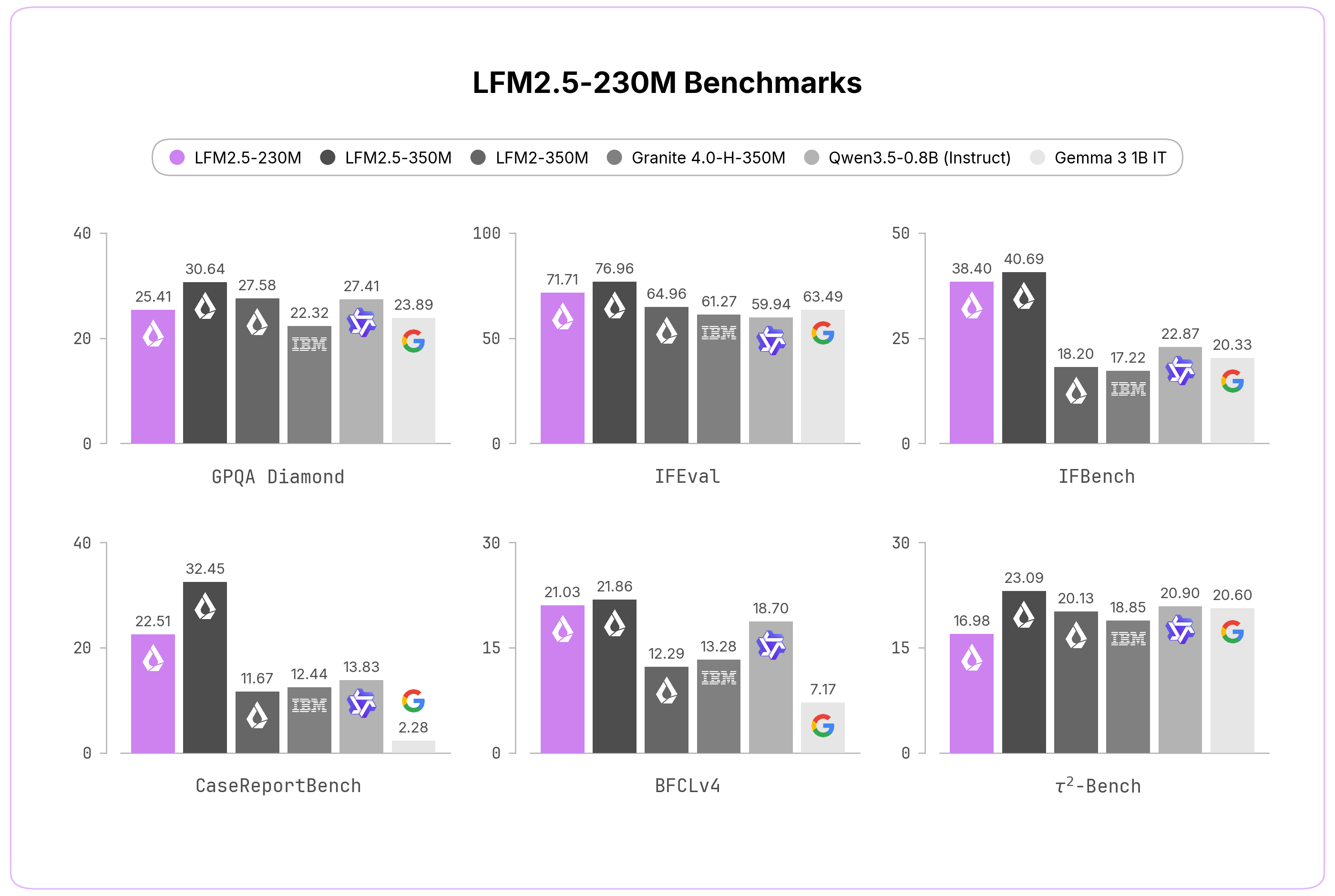
Benchmark performance
The following table shows LFM2.5-230M scores on a subset of benchmarks from the official evaluation, comparing favorably against larger models in its class.
| Benchmark | Score |
|---|---|
| GPQA Diamond | 25.41 |
| MMLU-Pro | 20.25 |
| IFEval | 71.71 |
| Multi-IF | 37.70 |
| BFCLv3 (function calling) | 43.26 |
| τ²-Bench Retail | 13.68 |
Deployment use cases
LFM2.5-230M has been deployed in real-world settings such as a skill-selection layer on a Unitree G1 humanoid robot running on an NVIDIA Jetson Orin, demonstrating its capability for decomposing natural-language instructions into multi-step tool calls. It is not recommended for reasoning-heavy workloads such as advanced math, code generation, or creative writing. Further details are available in the Liquid AI blog post.
best for
- ·On-device agentic pipelines and tool use
- ·Data extraction from structured or unstructured text
- ·Lightweight edge deployment on CPUs and mobile devices
FAQ
It is best for on-device agentic tasks, tool use, and data extraction. It is not recommended for reasoning-heavy workloads like advanced math or code generation.
It supports a context length of 32,768 tokens and has a vocabulary size of 65,536.
It supports English, Arabic, Chinese, French, German, Italian, Japanese, Korean, Portuguese, and Spanish.
Use the gigarouter OpenAI-compatible endpoint with your API key, sending a chat completion request with the model name LFM2.5-230M.
The recommended settings are temperature 0.1, top_k 50, and repetition_penalty 1.05.
We're benchmarking and onboarding LFM2.5-230M as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.