Wav2Vec 2.0 Large VoxRex Swedish
KBLab/wav2vec2-large-voxrex-swedish
published Mar 2022 · updated May 2025
Wav2Vec 2.0 Large VoxRex Swedish is an automatic speech recognition (ASR) model fine-tuned on Swedish radio broadcasts, NST, and Common Voice data.
specs
| Task | Automatic Speech Recognition (ASR) |
| Architecture | Wav2Vec 2.0 Large |
| Input Sampling Rate | 16 kHz |
| Language | Swedish |
| License | CC0-1.0 |
about this model
KBLab/wav2vec2-large-voxrex-swedish is an automatic speech recognition (ASR) model for Swedish, fine-tuned from the VoxRex large pretrained model on Swedish radio broadcasts, NST, and Common Voice data.
Key strengths
Without a language model, the model achieves a word error rate (WER) of 2.5% on the combined NST and Common Voice test set. On the Common Voice test set alone, the WER is 8.49% directly and 7.37% when used with a 4-gram language model. The base VoxRex model was pretrained for 400,000 updates on the P4-10k corpus, containing 10,000 hours of Swedish local public service radio and 1,500 hours of audiobooks and other speech from KB's collections.
Performance illustration
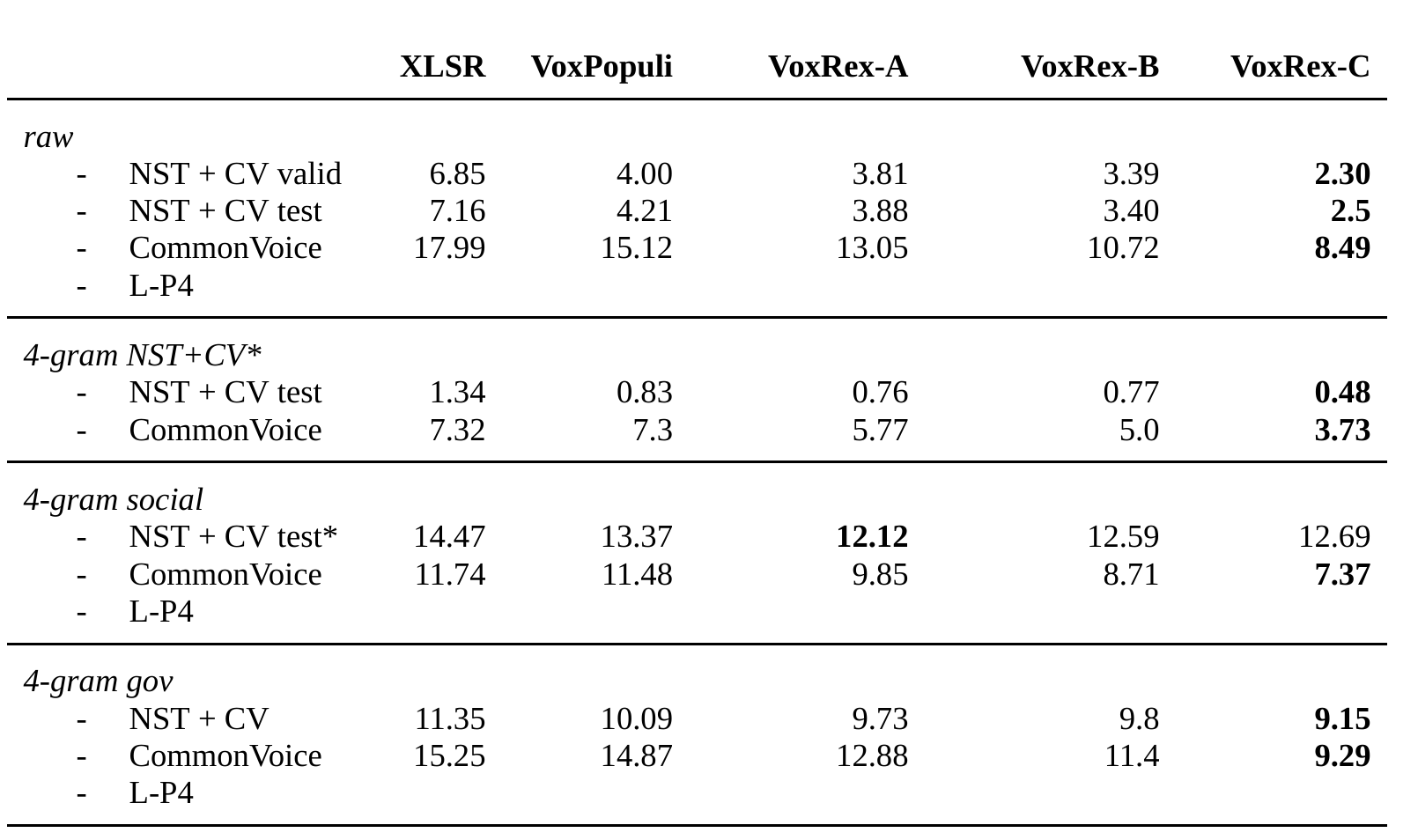 The chart shows performance without the additional 20,000 steps of Common Voice fine-tuning.
The chart shows performance without the additional 20,000 steps of Common Voice fine-tuning.

Usage notes
Speech input must be sampled at 16 kHz. The model is distributed under the CC0-1.0 license. Further details are described in the paper Hearing voices at the National Library – a speech corpus and acoustic model for the Swedish language (Fonetik 2022).
best for
- ·Transcribing Swedish radio broadcasts
- ·Automatic captioning of Swedish speech content
- ·Speech-to-text for Swedish cultural heritage archives
FAQ
On the NST + Common Voice test set the WER is 2.5%. On the Common Voice test set alone it is 8.49% without a language model and 7.37% with a 4-gram language model.
Use the gigarouter OpenAI-compatible endpoint with your API key. Send audio sampled at 16 kHz as input and receive transcription text in the response.
The model is released under the CC0-1.0 license, allowing free use for any purpose.
No, the model can be used directly without a language model as shown in the usage example. A 4-gram language model can optionally improve accuracy.
The model expects audio input sampled at 16 kHz. The example code uses torchaudio to resample from 48 kHz to 16 kHz if needed.
We're benchmarking and onboarding Wav2Vec 2.0 Large VoxRex Swedish as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.