E5-Omni 3B
Haon-Chen/e5-omni-3B
published Jan 2026 · updated Apr 2026
E5-Omni 3B is a visual-document-retrieval model that produces a single, unified embedding space for text, images, audio, and video, enabling accurate cross-modal retrieval.
specs
| Task | Omni-modal embedding and retrieval |
| Architecture | Based on Qwen2.5-Omni-3B |
| Parameters | 3B |
| License | MIT |
about this model
Haon-Chen/e5-omni-3B is an omni-modal embedding model that maps text, images, audio, and video into a unified embedding space, purpose-built for cross-modal retrieval tasks such as visual-document retrieval. It is built on Qwen2.5-Omni-3B and employs an explicit alignment recipe to overcome three common issues in omni-modal embeddings: modality-dependent similarity sharpness, in-batch negative hardness imbalance, and mismatched cross-modal statistics. The model combines modality-aware temperature calibration, a controllable negative curriculum with debiasing, and batch whitening with covariance regularization.
Benchmark Performance
On the MMEB-V2 and AudioCaps benchmarks, e5-omni-3B achieves consistent gains over strong bi-modal and omni-modal baselines.
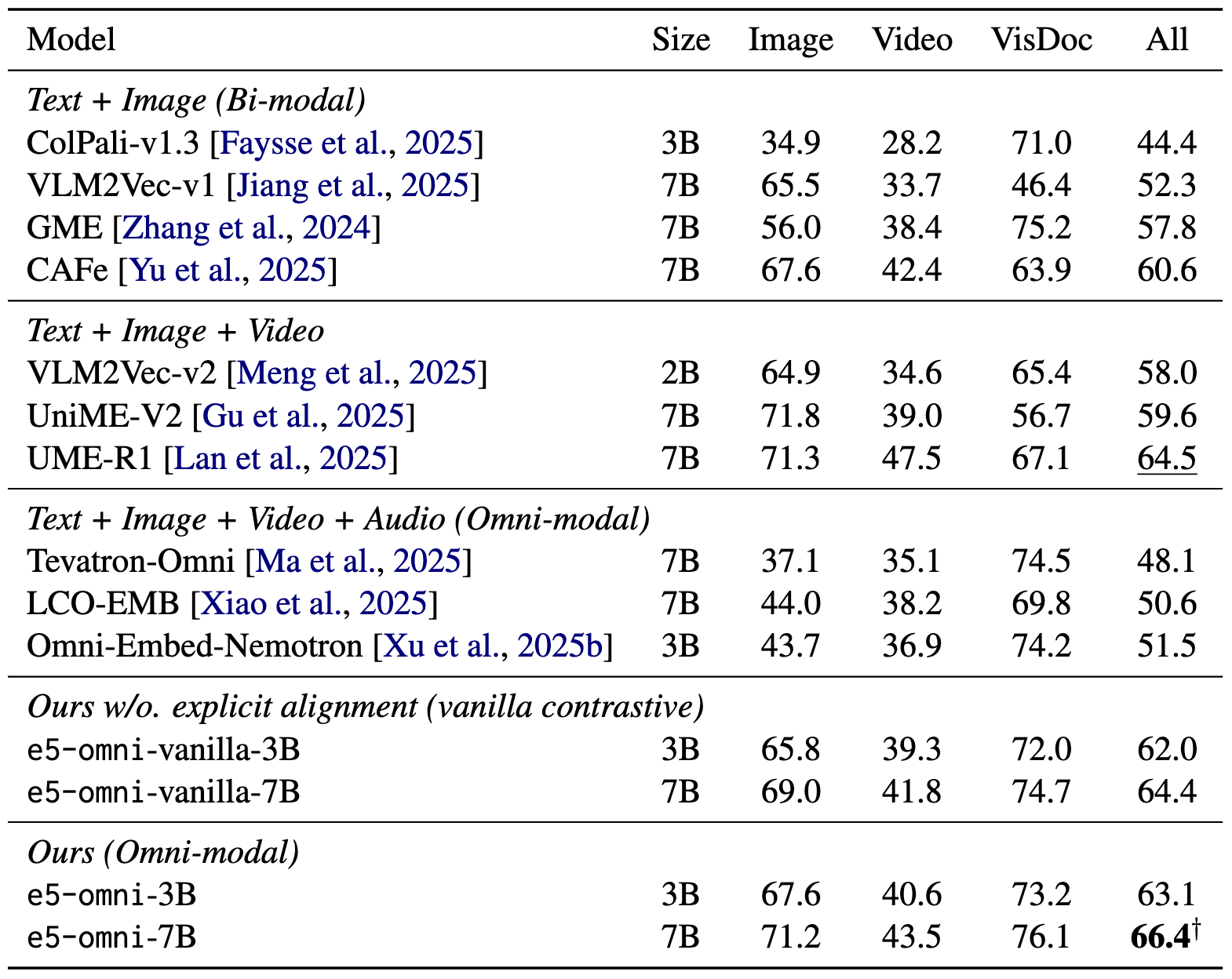
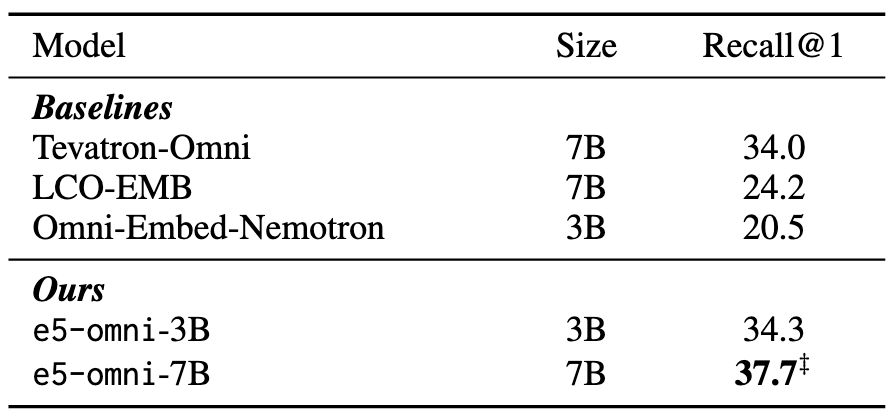
Key Capabilities
- Cross-modal retrieval across text, images, audio, and video from a single model.
- Produces normalized embeddings using the last hidden state of the final token for direct cosine similarity comparison.
- Supports multilingual text retrieval (demonstrated with Chinese queries).
- Document embedding can combine multiple modalities (e.g., text + video, image + audio) via a single dict input.
Additional Details
- Released under the MIT license.
- Associated paper: e5-omni: Explicit Cross-modal Alignment for Omni-modal Embeddings (arXiv, Jan 2026).
- A 7B variant (e5-omni-7B) is also available.
best for
- ·Cross-modal document retrieval (e.g., searching images or videos with text queries)
- ·Multilingual text retrieval and embedding
- ·Multimodal document search combining text, image, audio, and video inputs
FAQ
It supports text, image, audio, and video inputs, producing a unified embedding space for all.
It explicitly aligns modalities using temperature calibration, negative curriculum, and batch whitening, achieving consistent gains on MMEB-V2 and AudioCaps benchmarks.
It is released under the MIT license.
Use the gigarouter OpenAI-compatible endpoint with an API key to send queries and documents for embedding.
Pass a dict with keys like "text", "image", "audio", or "video" to encode combined modalities.
We're benchmarking and onboarding E5-Omni 3B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.