AltCLIP
BAAI/AltCLIP
published Nov 2022 · updated Apr 2025
AltCLIP is a bilingual Chinese-English zero-shot image-text representation model that aligns images with text using a modified CLIP architecture with an XLM-R text encoder.
specs
| Task | Zero-Shot Image-Text Representation & Retrieval |
| Architecture | ViT-L image encoder + XLM-R text encoder |
| Languages | Chinese, English |
| Model Size | 3.22 GB |
| Training Data | WuDao dataset & LAION-5B |
about this model
English
| Task | R@1 | R@5 | R@10 |
|---|---|---|---|
| Text-to-Image | 66.3 | 87.8 | 92.7 |
| Image-to-Text | 85.9 | 97.7 | 99.1 |
Chinese
| Task | R@1 | R@5 | R@10 |
|---|---|---|---|
| Text-to-Image | 63.7 | 86.3 | 92.1 |
| Image-to-Text | 84.7 | 97.4 | 98.7 |
 AltCLIP also serves as the text-image backbone for the AltDiffusion text-to-image generation model.
AltCLIP also serves as the text-image backbone for the AltDiffusion text-to-image generation model.

best for
- ·Bilingual (Chinese-English) image and text retrieval
- ·Zero-shot image classification and captioning
- ·Powering multilingual text-to-image generation (AltDiffusion)
FAQ
AltCLIP is a bilingual Chinese-English zero-shot image-text model based on CLIP, using XLM-R as its text encoder for multilingual capabilities.
It supports Chinese and English. A variant AltCLIP-m9 also supports Spanish, French, Russian, Japanese, Korean, Arabic, and Italian.
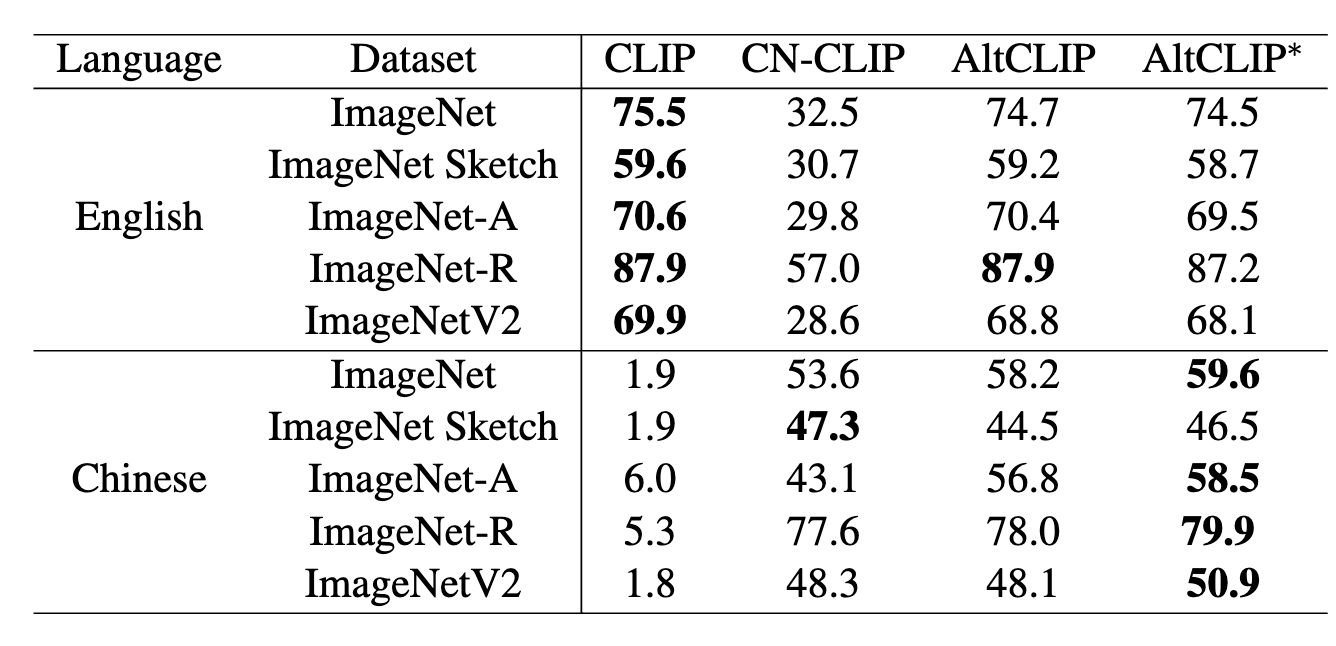
AltCLIP achieves similar performance to CLIP on English tasks while adding strong Chinese and multilingual capabilities, setting state-of-the-art on Chinese retrieval benchmarks.
Input: text strings and images (as PIL or URLs). Output: similarity scores or embeddings for text-image pairs.
Use the gigarouter OpenAI-compatible endpoint with an API key, sending prompts and images as specified in the documentation.
We're benchmarking and onboarding AltCLIP as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.