ARK ASR 3B
AutoArk-AI/ARK-ASR-3B
published Jun 2026 · updated Jun 2026
ARK ASR 3B is a multilingual automatic speech recognition model that combines a Whisper-style audio encoder, an MLP adapter, and a Qwen decoder to transcribe speech in 19 languages.
specs
| Task | automatic speech recognition |
| Architecture | audio-capable autoregressive Transformers with Whisper-style encoder, MLP adapter, and Qwen decoder |
| Parameters | 3B |
| License | Apache-2.0 |
about this model
ARK-ASR-3B is an automatic speech recognition model that combines a Whisper-style audio encoder with a 3-billion-parameter Qwen decoder via an MLP adapter.
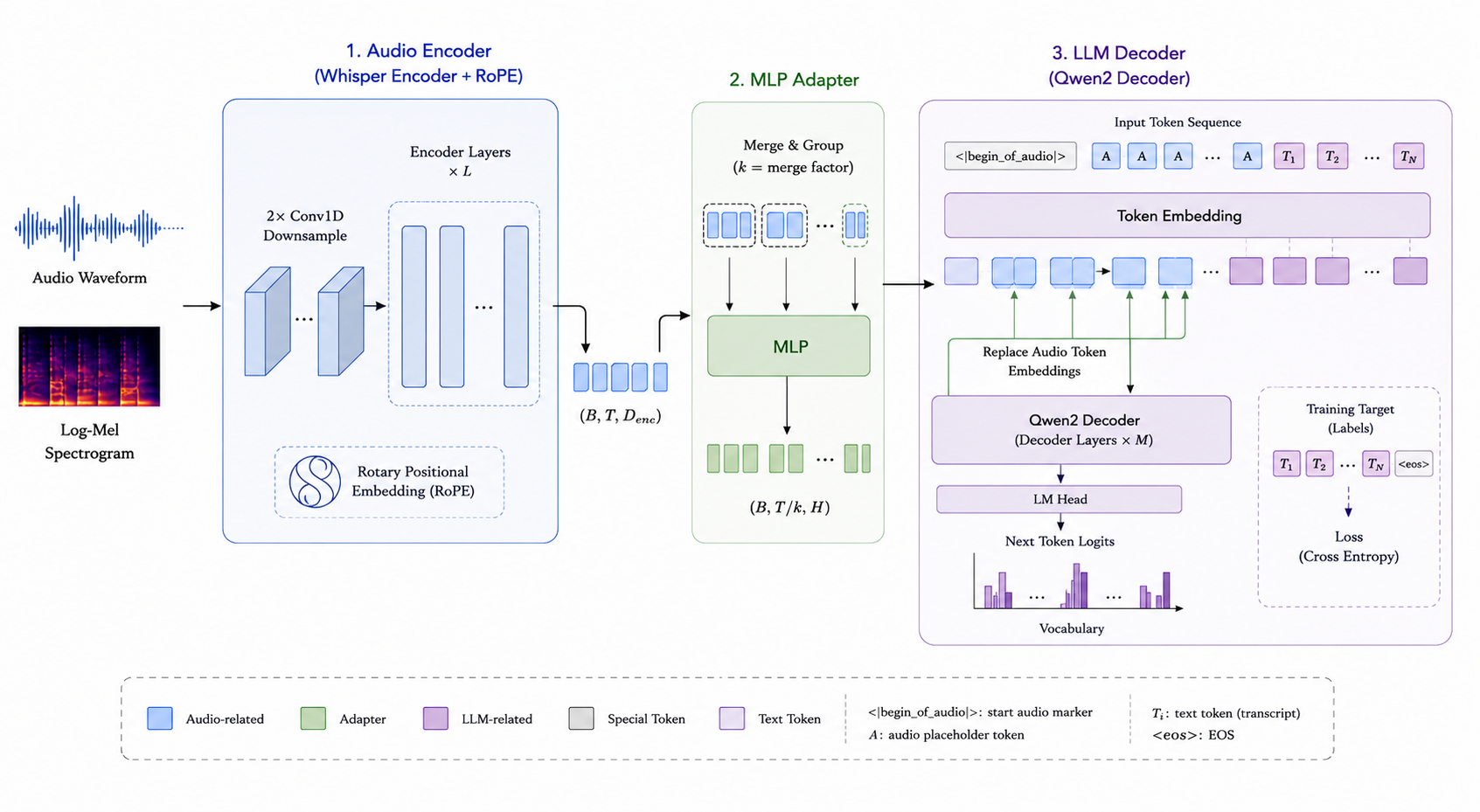
The model supports 19 languages: Chinese, English, German, Japanese, French, Korean, Spanish, Polish, Italian, Romanian, Hungarian, Czech, Dutch, Finnish, Croatian, Slovak, Slovene, Estonian, and Lithuanian. Audio is processed at 16 kHz and transcribed autoregressively. The decoder replaces audio placeholder token embeddings with encoder output before generation, with custom token filtering for ASR.
English short-form benchmark (Open ASR Leaderboard)
ARK-ASR-3B achieves an average word error rate of 5.04% and real-time factor (RTFx) of 490.98 across seven datasets, claiming state-of-the-art on the Hugging Face Open ASR Leaderboard English short-form benchmark at the time of release.
| Dataset | WER |
|---|---|
| AMI | 8.79% |
| Earnings22 | 8.23% |
| GigaSpeech | 6.98% |
| LibriSpeech Clean | 1.03% |
| LibriSpeech Other | 2.35% |
| SPGISpeech | 2.46% |
| VoxPopuli | 5.47% |
| Average | 5.04% |
Chinese CER
| Dataset | CER |
|---|---|
| AISHELL-1 | 1.80% |
| WenetSpeech test meeting | 4.97% |
| WenetSpeech test-net | 4.58% |
The model is trained using on-policy distillation from a stronger teacher (see arXiv:2605.28139). All evaluation follows the Hugging Face open_asr_leaderboard codebase. ARK-ASR-3B is hosted on Gigarouter as a managed, OpenAI-compatible API – no local installation or GPU management required.
best for
- ·Multilingual transcription of English and Chinese speech
- ·Real-time ASR with vLLM-backed serving
- ·Batch inference on long audio files (up to 30 seconds per sample)
FAQ
It supports Chinese, English, German, Japanese, French, Korean, Spanish, Polish, Italian, Romanian, Hungarian, Czech, Dutch, Finnish, Croatian, Slovak, Slovene, Estonian, and Lithuanian.
The model card reports an average WER of 5.04% across AMI, Earnings22, GigaSpeech, LibriSpeech, SPGISpeech, and VoxPopuli. Note: this result is not yet reflected in the official leaderboard CSV.
Use the gigarouter OpenAI-compatible endpoint with your API key. The model accepts 16 kHz mono audio and returns transcribed text. Refer to the gigarouter documentation for the exact endpoint and request format.
Load the model with <code>trust_remote_code=True</code> in Hugging Face Transformers, using bfloat16 on CUDA and SDPA attention. The official inference script handles processor, tokenizer, and generation cleanup.
Yes, the repository includes a vLLM adapter that exposes both a compact /asr endpoint and an OpenAI-style /v1/audio/transcriptions endpoint. See the vLLM serving section in the model card.
We're benchmarking and onboarding ARK ASR 3B as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.