GTE Multilingual Reranker Base
Alibaba-NLP/gte-multilingual-reranker-base
published Jul 2024 · updated Jul 2025
GTE Multilingual Reranker Base is a rerank model that achieves state-of-the-art multilingual retrieval performance with a fast encoder-only transformer architecture supporting up to 8192 tokens and over 70 languages.
specs
| Task | Reranking |
| Architecture | Encoder-only Transformer |
| Parameters | 306M |
| Max Input Tokens | 8192 |
about this model
Performance and Efficiency
The model achieves state-of-the-art results on multilingual retrieval benchmarks among rerankers of comparable size. According to the accompanying paper (EMNLP 2024 Industry Track), the reranker matches the performance of the larger BGE-M3 models and surpasses them on long-context retrieval benchmarks. Its encoder-only design provides an approximately 10x inference speed advantage over decoder-only LLM-based rerankers (e.g., gte-qwen2-1.5b-instruct) and requires lower hardware resources.
Architecture and Training
The underlying text encoder is pre-trained with a native 8,192-token context (compared to 512 tokens for previous multilingual encoders like XLM-R) and enhanced with Rotary Position Embedding (RoPE) and unpadding optimization. The reranker is trained via contrastive learning on a hybrid of text representation and cross-encoder objectives.
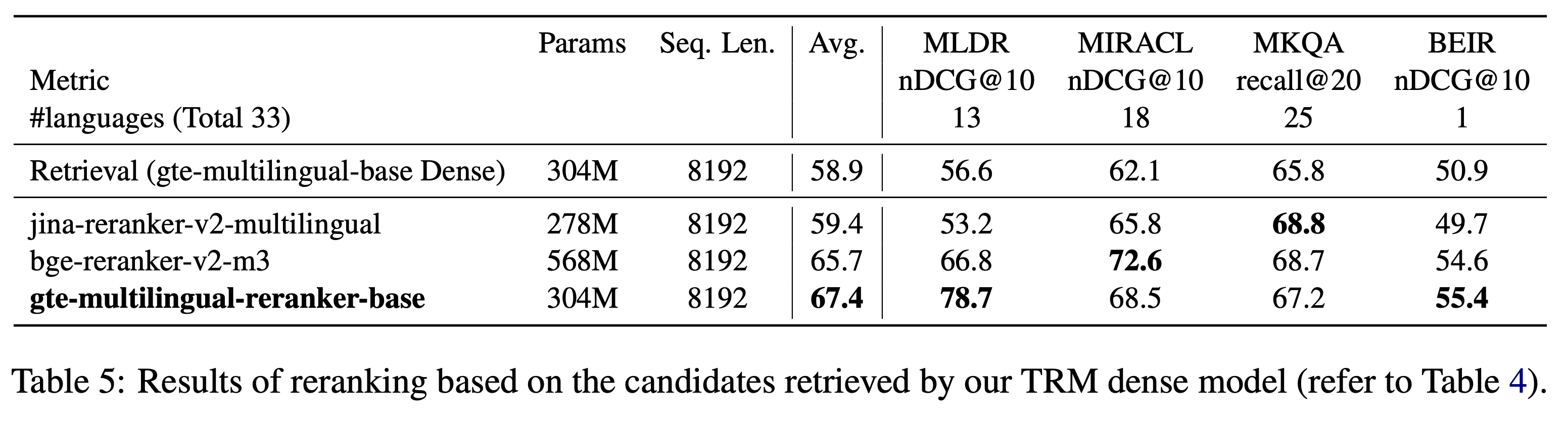
Benchmark Results
Evaluation on multiple text retrieval datasets demonstrates the model's effectiveness. Detailed experimental results are available in the paper.
This model is hosted as a managed, OpenAI-compatible API on gigarouter, requiring no local infrastructure or model loading.
best for
- ·Multilingual document retrieval reranking
- ·Long-context search (up to 8192 tokens)
- ·Cross-lingual question answering
FAQ
8192 tokens.
Over 70 languages.
It matches the performance of large-sized BGE-M3 models and achieves better results on long-context retrieval benchmarks.
Use the OpenAI-compatible endpoint with your gigarouter API key.
Yes, its encoder-only architecture provides roughly 10x inference speed increase compared to decoder-only models.
We're benchmarking and onboarding GTE Multilingual Reranker Base as a hosted, OpenAI-compatible API. Sign in for free credit and be ready when it lands, or tell us you want it and we'll prioritize it.